이 게시글은 프로젝트를 진행하면서 발생한 쿼리를 최적화하는 과정에 대한 내용을 담고 있습니다.
우선 요구 사항은 아래와 같습니다.
유저는 자신만의 문제를 등록할 수 있다. 유저가 등록한 문제는 등록한 유저 본인만이 풀 수 있어야 하고 관리자가 등록한 기본 문제들도 풀 수 있다. 이때 api를 요청할 때마다 정말 랜덤한 문제가 N개씩 불러와져야 한다.
지금부터 리팩토링하면서 코드가 어떻게 변경되었는지 설명드리겠습니다.
각각의 단계에서의 성능 비교에 대한 내용은 글의 마지막 부분에 있습니다.
기존 코드
처음 이 요구사항을 들었을 때 정말 랜덤한 문제를 어떻게 가져올 수 있을까에 대한 고민이 있었습니다. 따라서 처음 생각했던 방식은 해당 유저가 풀 수 있는 문제가 몇 개인지 확인 후 그 문제가 K개라고 하면 0 ~ K - 1 사이의 난수를 생성 후 각각의 난수에 해당하는 page를 PageRequest로 불러오자는 것이었습니다.
위와 같은 방식을 고민한 이유가 findAll을 한 다음 난수를 N개 발생시켜서 해당 난수 번호의 index에 있는 값을 가져오면 쿼리는 findAll 한번만 하면 되지만 만약 해당 유저가 풀 수 있는 문제가 굉장히 많다면 OOM(Out Of Memory)의 문제가 발생할 수 있지 않을까를 고민하여 문제마다 쿼리를 만드는 방식을 생각하였습니다.
또한 가장 처음에 받았던 요구 사항은 N개의 문제가 아니라 1개의 문제만 보여주면 된다였지만 1개의 문제는 너무 적기 때문에 N개의 문제를 유저에게 보여주면 좋겠다는 변경점이 있어 1개의 문제에 대해서 만들어두었던 코드를 많은 고민 없이 N개로 변경해서 비효율성이 증대되었습니다.
처음 생각했던 방식에 대한 코드는 아래와 같습니다.
ImageQuizService 코드
public ImageQuizSolveListResponse selectRandomImageQuizList(Long memberId, Integer quizNum) {
Member member = memberRepository.findById(memberId)
.orElseThrow(() -> new MemberNotFoundException(MEMBER_NOT_FOUND));
int totalQuizNum = getImageQuizCount(member);
List<ImageQuizSolveResponse> imageQuizSolveResponseList =
RandNumUtil.generateRandomNumbers(0, totalQuizNum - 1, quizNum).stream()
.map(quizIdx -> generateRandomPageWithCategory(member, quizIdx))
.map(ImageQuizSolveResponse::from)
.toList();
return new ImageQuizSolveListResponse(imageQuizSolveResponseList);
}
private ImageQuiz generateRandomPageWithCategory(Member member, int quizIdx) {
return imageQuizRepository.findSingleResultByMember(member, PageRequest.of(quizIdx, 1)).get(0);
}
private int getImageQuizCount(Member member) {
return imageQuizRepository.countByMemberOrAdmin(member);
}ImageQuizRepository 코드
@Query("SELECT count(*) FROM ImageQuiz iq WHERE iq.member = :member OR iq.member.role = 'ADMIN'")
Integer countByMemberOrAdmin(Member member);
@Query("SELECT iq FROM ImageQuiz iq WHERE iq.member = :member OR iq.member.role = 'ADMIN'")
List<ImageQuiz> findSingleResultByMember(Member member, Pageable pageable);RandNumUtil 코드
/**
* 원하는 개수의 난수를 생성
*/
public class RandNumUtil {
private static final Random random = new Random();
/**
* 난수 List 생성 메서드
*/
public static List<Integer> generateRandomNumbers(int startNum, int endNum, int size) {
if (size > (endNum - startNum + 1)) {
throw new IllegalArgumentException("요청된 크기가 가능한 난수 범위를 초과합니다.");
}
Set<Integer> randNumSet = new HashSet<>();
// 서로 다른 난수 들이 size 개수 만큼 될 때까지 반복
while (randNumSet.size() < size) {
int randNum = generateRandomNum(startNum, endNum);
randNumSet.add(randNum);
}
// Set 을 List 로 변환 후 반환
return new ArrayList<>(randNumSet);
}
private static int generateRandomNum(int startNum, int endNum) {
return startNum + random.nextInt(endNum - startNum + 1);
}
}
위의 코드의 발생 쿼리는 아래와 같습니다. 1번의 요청을 유저가 하고 5개의 문제를 한 번에 푸는 상황입니다.
Hibernate: //1
select
m1_0.member_id,
m1_0.birth_date,
m1_0.created_date,
m1_0.email,
m1_0.gender,
m1_0.last_modified_date,
m1_0.name,
m1_0.oauth_type,
m1_0.role,
m1_0.score,
m1_0.social_id
from
member m1_0
where
m1_0.member_id=?
Hibernate: //2
select
count(*)
from
image_quiz iq1_0
join
member m1_0
on m1_0.member_id=iq1_0.member_id
where
iq1_0.member_id=?
or m1_0.role='ADMIN'
Hibernate: //3
select
iq1_0.quiz_id,
iq1_0.answer,
iq1_0.quiz_level,
iq1_0.member_id,
iq1_0.category,
iq1_0.rand_val,
iq1_0.file_name,
iq1_0.folder_name,
iq1_0.s3_url,
iq1_0.title
from
image_quiz iq1_0
join
member m1_0
on m1_0.member_id=iq1_0.member_id
where
iq1_0.member_id=?
or m1_0.role='ADMIN'
limit
?, ?
Hibernate: //4
select
iq1_0.quiz_id,
iq1_0.answer,
iq1_0.quiz_level,
iq1_0.member_id,
iq1_0.category,
iq1_0.rand_val,
iq1_0.file_name,
iq1_0.folder_name,
iq1_0.s3_url,
iq1_0.title
from
image_quiz iq1_0
join
member m1_0
on m1_0.member_id=iq1_0.member_id
where
iq1_0.member_id=?
or m1_0.role='ADMIN'
limit
?, ?
Hibernate: //5
select
iq1_0.quiz_id,
iq1_0.answer,
iq1_0.quiz_level,
iq1_0.member_id,
iq1_0.category,
iq1_0.rand_val,
iq1_0.file_name,
iq1_0.folder_name,
iq1_0.s3_url,
iq1_0.title
from
image_quiz iq1_0
join
member m1_0
on m1_0.member_id=iq1_0.member_id
where
iq1_0.member_id=?
or m1_0.role='ADMIN'
limit
?, ?
Hibernate: //6
select
iq1_0.quiz_id,
iq1_0.answer,
iq1_0.quiz_level,
iq1_0.member_id,
iq1_0.category,
iq1_0.rand_val,
iq1_0.file_name,
iq1_0.folder_name,
iq1_0.s3_url,
iq1_0.title
from
image_quiz iq1_0
join
member m1_0
on m1_0.member_id=iq1_0.member_id
where
iq1_0.member_id=?
or m1_0.role='ADMIN'
limit
?, ?
Hibernate: //7
select
iq1_0.quiz_id,
iq1_0.answer,
iq1_0.quiz_level,
iq1_0.member_id,
iq1_0.category,
iq1_0.rand_val,
iq1_0.file_name,
iq1_0.folder_name,
iq1_0.s3_url,
iq1_0.title
from
image_quiz iq1_0
join
member m1_0
on m1_0.member_id=iq1_0.member_id
where
iq1_0.member_id=?
or m1_0.role='ADMIN'
limit
?, ?
요청을 했을 때 5개의 문제만 풀려고 했는데도 7번의 쿼리가 발생하는 것을 확인할 수 있었습니다.
이렇게 문제마다 쿼리가 발생하는 것은 성능상 굉장히 좋지 않다는 생각을 하여 이 쿼리의 수를 줄일 수 있는 방식을 생각해보았습니다.
1차 리팩토링(ORDER BY RAND()를 사용, 쿼리 수 줄이기)
제가 기존 코드를 보면서 생각한 것은 너무 많은 쿼리가 발생한다는 것이었습니다. 따라서 우선 저는 쿼리의 수를 줄이는 데 집중을 하였습니다.
제가 생각한 방식은 mysql에서 제공하는 native query인 rand()를 사용하여 정렬 후, limit를 사용하여 N개의 문제만 가져오면 되지 않을까? 였습니다.
따라서 native query를 작성하였고 작성한 코드는 아래와 같습니다.
ImageQuizService
public ImageQuizSolveListResponse selectRandomImageQuizList(Long memberId, Integer quizNum) {
List<ImageQuizSolveResponse> imageQuizSolveResponseList =
imageQuizRepository.findRandomQuizzesByMemberOrAdmin(memberId, quizNum).stream()
.map(ImageQuizSolveResponse::from)
.toList();
return new ImageQuizSolveListResponse(imageQuizSolveResponseList);
}ImageQuizRepository
@Query(value = "SELECT iq.* FROM image_quiz iq " +
"JOIN member m ON iq.member_id = m.member_id " +
"WHERE iq.member_id = :memberId OR m.role = 'admin' " +
"ORDER BY RAND() LIMIT :limit", nativeQuery = true)
List<ImageQuiz> findRandomQuizzesByMemberOrAdmin(Long memberId, int limit);
위와 같은 방식으로 코드를 변경한 후 1번의 요청이 올 때 발생하는 쿼리는 아래와 같습니다.
Hibernate:
SELECT
iq.*
FROM
image_quiz iq
JOIN
member m
ON iq.member_id = m.member_id
WHERE
iq.member_id = ?
OR m.role = 'admin'
ORDER BY
RAND()
LIMIT
?
기존 7번이던 쿼리가 1번으로 줄었습니다. DB에 접근하는 양이 줄었기 때문에 성능이 향상되었습니다. 성능이 어떻게 향상되었는지는 마지막에 상세히 보여 드리겠습니다.
하지만 이 방식은 ORDER BY RAND()를 사용했기 때문에 고정적으로 난수를 생성 + 정렬하는 비용이 든다는 문제가 있었고 항상 image_quiz 테이블과 member 테이블이 join 연산이 일어난다는 문제가 있었습니다.
따라서 이를 해결하기 위해서 난수를 미리 생성하여 image_quiz 테이블에 저장하고자 합니다.
또한 join 연산이 일어나는 이유가 member 테이블에서 role이 admin인 즉 관리자가 생성한 애플리케이션이 제공하는 기본 문제인가를 확인하기 위해서였는데 join이 발생하지 않게 하기 위해서 role이 admin인 유저가 등록한 문제는 is_default라는 column을 만들어서 저장해 두면 join을 하지 않아도 될 것이라 생각해 이 부분을 수정하고자 하였습니다.
2차 리팩토링(JOIN 제거, RAND() 제거)
이번에는 JOIN을 제거, RAND()를 제거하기 위해서 coloumn을 ImageQuiz에 추가하였습니다.
변경 후 코드는 아래와 같습니다.
ImageQuizService
public ImageQuizSolveListResponse selectRandomImageQuizList(Long memberId, Integer quizNum) {
long count = imageQuizRepository.countByMemberId(memberId);
PageRequest pageRequest = makeRandomPageRequest(count, quizNum);
List<ImageQuizSolveResponse> imageQuizSolveResponseList =
imageQuizRepository.findRandomQuizzesByMember(memberId, pageRequest).stream()
.map(ImageQuizSolveResponse::from)
.toList();
return new ImageQuizSolveListResponse(imageQuizSolveResponseList);
}
private PageRequest makeRandomPageRequest(long count, int quizNum) {
return PageRequest.of(ThreadLocalRandom.current().nextInt((int) (count / quizNum)), quizNum);
}ImageQuizRepository
@Query("SELECT count(*) FROM ImageQuiz iq "
+ "WHERE iq.isDefault = TRUE OR iq.member.memberId = :memberId")
Long countByMemberId(Long memberId);
@Query("SELECT iq FROM ImageQuiz iq "
+ "WHERE iq.isDefault = TRUE OR iq.member.memberId = :memberId "
+ "ORDER BY iq.randVal")
List<ImageQuiz> findRandomQuizzesByMember(Long memberId, PageRequest request);ImageQuiz
@Table(name = "image_quiz")
@Getter
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class ImageQuiz {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "quiz_id")
private Long quizId;
@Column(name = "category")
@Enumerated(EnumType.STRING)
private QuizCategory quizCategory;
@Column(name = "answer", length = 20)
private String answer;
@Column(name = "title", length = 30)
private String title;
@Embedded
private S3Info s3Info;
@Column(name = "quiz_level")
@Enumerated(EnumType.STRING)
private Level level;
@Column(name = "rand_val")
private Long randVal;
@JoinColumn(name = "member_id")
@ManyToOne(fetch = FetchType.LAZY)
private Member member;
@Column(name = "is_default")
private Boolean isDefault;
@OneToMany(mappedBy = "imageQuiz", orphanRemoval = true)
private List<QuizSolved> quizSolvedList = new ArrayList<>();
@Builder
public ImageQuiz(QuizCategory quizCategory, String answer, String title, S3Info s3Info, Level level,
Member member, Boolean isDefault) {
this.quizCategory = quizCategory;
this.answer = answer;
this.title = title;
this.s3Info = s3Info;
this.level = level;
this.member = member;
this.isDefault = isDefault;
this.randVal = ThreadLocalRandom.current().nextLong(Long.MAX_VALUE);
}
}
1차 리팩토링 후의 코드에서는 rand()를 요청마다 실행하여 문제마다 새로운 난수값을 생성해 준 다음에 이 값으로 정렬하고 가장 앞에 있는 N개의 문제만 가져오면 되었습니다.
하지만 이제 난수 값을 미리 만들어 두었기 때문에 문제마다 주어진 난수 값이 몇 번의 요청에도 같은 값을 유지하고 있습니다. 따라서 저는 기존의 요구 사항인 정말 랜덤의 문제 N개를 유저에게 보여주기 위해서 count 쿼리를 발생시켰습니다.
count 쿼리를 발생시킨 이유는 DB에 유저가 풀 수 있는 문제가 몇 개인지 확인 후 해당 문제들을 N개 단위로 잘라서 랜덤한 index에 해당하는 세트의 문제를 가져오기 위해서였습니다.
문제가 총 얼마나 있는지를 확인해야 풀 수 없는 문제가 존재하지 않기 때문에 count 쿼리를 진행 후 랜덤한 문제를 가져오게 했습니다.
위의 코드에 대한 쿼리는 아래와 같습니다.
Hibernate: //1
select
count(*)
from
image_quiz iq1_0
where
iq1_0.is_default=1
or iq1_0.member_id=?
Hibernate: //2
select
iq1_0.quiz_id,
iq1_0.answer,
iq1_0.is_default,
iq1_0.quiz_level,
iq1_0.member_id,
iq1_0.category,
iq1_0.rand_val,
iq1_0.file_name,
iq1_0.folder_name,
iq1_0.s3_url,
iq1_0.title
from
image_quiz iq1_0
where
iq1_0.is_default=1
or iq1_0.member_id=?
order by
iq1_0.rand_val
limit
?, ?
요청마다 count 쿼리를 포함한 2번의 쿼리가 발생한다는 단점이 있지만 미리 난수를 생성 + join이 진행되지 않기 때문에 성능이 조금 더 향상되었습니다.
하지만 여전히 count 쿼리가 계속 나간다는 문제와 너무 많은 column들이 select 되기 때문에 불필요한 데이터들을 가져오는 비용이 크다는 문제가 있습니다.
따라서 위의 문제를 해결하기 위해서 마지막 리팩토링을 진행하였습니다.
3차 리팩토링(Map으로 유저의 문제 수 기억, DTO projection, covering index)
이번에는 count 쿼리를 발생시키지 않기 위해서 유저가 풀 수 있는 문제 수를 Map으로 저장하자는 생각을 하였습니다.
또한 너무 많은 column이 조회되기 때문에 꼭 필요한 column들만 가져오는 방식으로 리팩토링을 진행하였습니다.
마지막으로 rand_val로 정렬 후 조회에 필요한 column들을 바로 가져오자는 생각을 하였습니다. rand_val에 index를 설정하면 ORDER BY에 의한 정렬을 할 때 미리 설정된 non-clustered index에서 값을 가져오면 됩니다. 이때 non-clustered index에 의해서 정렬이 된 다음에 필요한 column들에 해당하는 값을 가져오기 위해서는 본래 데이터가 있는 영역으로 접근이 필요합니다. 따라서 이와 같은 불필요한 접근을 막기 위해서 필요한 column들을 추가로 index에 설정하였고 모든 필요한 column들을 composite index로 설정하였기 때문에 covering index가 되었습니다.
마지막 리팩토링 후 코드는 아래와 같습니다.
ImageQuiz
@Table(name = "image_quiz", indexes = {
@Index(name = "idx_image_quiz_rand_val", columnList = "rand_val, is_default, member_id, answer, s3_url")
})
@Getter
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class ImageQuiz {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "quiz_id")
private Long quizId;
@Column(name = "category")
@Enumerated(EnumType.STRING)
private QuizCategory quizCategory;
@Column(name = "answer", length = 20)
private String answer;
@Column(name = "title", length = 30)
private String title;
@Embedded
private S3Info s3Info;
@Column(name = "quiz_level")
@Enumerated(EnumType.STRING)
private Level level;
@Column(name = "rand_val")
private Long randVal;
@JoinColumn(name = "member_id")
@ManyToOne(fetch = FetchType.LAZY)
private Member member;
@Column(name = "is_default")
private Boolean isDefault;
@OneToMany(mappedBy = "imageQuiz", orphanRemoval = true)
private List<QuizSolved> quizSolvedList = new ArrayList<>();
@Builder
public ImageQuiz(QuizCategory quizCategory, String answer, String title, S3Info s3Info, Level level,
Member member, Boolean isDefault) {
this.quizCategory = quizCategory;
this.answer = answer;
this.title = title;
this.s3Info = s3Info;
this.level = level;
this.member = member;
this.isDefault = isDefault;
this.randVal = ThreadLocalRandom.current().nextLong(Long.MAX_VALUE);
}
}ImageQuizService
public ImageQuizSolveListResponse selectRandomImageQuizList(Long memberId, Integer quizNum) {
long count = imageQuizCountCache.get(memberId);
PageRequest pageRequest = makeRandomPageRequest(count, quizNum);
List<ImageQuizSolveResponse> imageQuizSolveResponseList =
imageQuizRepository.findRandomQuizzesByMember(memberId, pageRequest);
return ImageQuizSolveListResponse.from(imageQuizSolveResponseList);
}
private PageRequest makeRandomPageRequest(long count, int quizNum) {
return PageRequest.of(ThreadLocalRandom.current().nextInt((int) (count / quizNum)), quizNum);
}ImageQuizRepository
@Query("SELECT count(*) FROM ImageQuiz iq "
+ "WHERE iq.isDefault = TRUE OR iq.member.memberId = :memberId")
Long countByMemberId(Long memberId);
@Query("SELECT new soongsil.kidbean.server.imagequiz.dto.response.ImageQuizSolveResponse(iq.quizId, iq.answer, iq.s3Info.s3Url) "
+ "FROM ImageQuiz iq "
+ "WHERE iq.isDefault = TRUE OR iq.member.memberId = :memberId "
+ "ORDER BY iq.randVal")
List<ImageQuizSolveResponse> findRandomQuizzesByMember(Long memberId, PageRequest request);ImageQuizCountCache
@RequiredArgsConstructor
@Component
public class ImageQuizCountCache {
private final ImageQuizRepository imageQuizRepository;
private static final Map<Long, Long> imageQuizCountCache = new ConcurrentHashMap<>();
public void plusCount(Long memberId) {
if (imageQuizCountCache.containsKey(memberId)) {
imageQuizCountCache.put(memberId, imageQuizCountCache.get(memberId) + 1);
}
}
public void minusCount(Long memberId) {
if (imageQuizCountCache.containsKey(memberId)) {
imageQuizCountCache.put(memberId, imageQuizCountCache.get(memberId) - 1);
}
}
public Long get(Long memberId) {
// 캐시에서 값을 가져옴
Long count = imageQuizCountCache.get(memberId);
// 캐시에 값이 없으면 ImageQuizRepository에서 값을 가져와 캐시에 넣음
if (count == null) {
count = imageQuizRepository.countByMemberId(memberId);
if (count != null) {
imageQuizCountCache.put(memberId, count);
}
}
return count;
}
}ImageQuizSolveListReponse
public record ImageQuizSolveListResponse(
List<ImageQuizSolveResponse> imageQuizSolveResponseList
) {
public static ImageQuizSolveListResponse from(List<ImageQuizSolveResponse> imageQuizSolveResponseList) {
return new ImageQuizSolveListResponse(imageQuizSolveResponseList);
}
}Map으로 유저가 풀 수 있는 문제 수를 기억하게 만들었기 때문에 유저당 count 쿼리가 1번씩만 나가게 되어 더 효율적으로 변경되었습니다.
또한 DB에서 필요한 값만 가져와서 DTO에 바로 넣었기 때문에 성능이 향상되었고, covering index 덕분에 불필요한 접근 또한 줄었습니다.
위의 코드에 의한 쿼리는 아래와 같습니다.
Hibernate: //해당 유저가 요청을 보낸 적이 없는 경우만 호출
select
count(*)
from
image_quiz iq1_0
where
iq1_0.is_default=1
or iq1_0.member_id=?
Hibernate:
select
iq1_0.quiz_id,
iq1_0.answer,
iq1_0.s3_url
from
image_quiz iq1_0
where
iq1_0.is_default=1
or iq1_0.member_id=?
order by
iq1_0.rand_val
limit
?, ?
※DTO projection을 사용하는 경우 entity를 가져오는 것이 아니라서 영속성 컨텍스트에 저장이 되지 않기 때문에 추후 entity graph 등 영속성 컨텍스트에서 지원하는 기능을 사용할 수 없으니 조심해서 사용해야 합니다.
성능 비교
이제 제가 각각의 리팩토링 단계마다 성능이 어떻게 향상되었는지에 대해서 보여드리도록 하겠습니다.
저는 서버에 요청을 발생시키고 그 요청에 대한 분석을 진행하기 위해서 k6를 사용하였습니다.
import http from 'k6/http';
import { sleep } from 'k6';
export const options = {
vus: 50,
duration: '20s',
};
export default function() {
const url = 'https://server-domain/quiz/image/solve';
const params = {
headers: {
'Authorization': 'Bearer access-token'
}
};
http.get(url, params);
sleep(1);
}위와 같은 script를 이용하여 k6를 동작시켰습니다.
현재 테스트 조건은 유저가 50명 존재하는데 이 유저들이 20초 동안 1초에 1번의 요청을 보내는 조건입니다.
테스트는 유저는 1000명으로 항상 동일하고, 문제의 수는 31개, 1550개, 6200개, 31000개, 62000개, 155000개로 각각 진행했습니다.
결과는 155000개로 진행했을 때는 위주로 설명 후 마지막에 그래프로 전체적인 결과를 보여드리겠습니다.
우선 리팩토링 전의 결과입니다.
Member 1000명 ImageQuiz 155000개
/\\ |‾‾| /‾‾/ /‾‾/
/\\ / \\ | |/ / / /
/ \\/ \\ | ( / ‾‾\\
/ \\ | |\\ \\ | (‾) |
/ __________ \\ |__| \\__\\ \\_____/ .io
execution: local
script: script.js
output: -
scenarios: (100.00%) 1 scenario, 50 max VUs, 50s max duration (incl. graceful stop):
* default: 50 looping VUs for 20s (gracefulStop: 30s)
data_received..................: 119 kB 3.6 kB/s
data_sent......................: 38 kB 1.1 kB/s
http_req_blocked...............: avg=4.85ms min=0s med=0s max=12.65ms p(90)=10.73ms p(95)=11.21ms
http_req_connecting............: avg=687.49µs min=0s med=0s max=3.53ms p(90)=2.15ms p(95)=2.15ms
http_req_duration..............: avg=11.15s min=2.84s med=12.48s max=16.83s p(90)=13.96s p(95)=14.22s
{ expected_response:true }...: avg=11.15s min=2.84s med=12.48s max=16.83s p(90)=13.96s p(95)=14.22s
http_req_failed................: 0.00% ✓ 0 ✗ 111
http_req_receiving.............: avg=2.43ms min=0s med=0s max=248.78ms p(90)=999.3µs p(95)=1.02ms
http_req_sending...............: avg=250.27µs min=0s med=0s max=1.48ms p(90)=977.7µs p(95)=977.7µs
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=11.14s min=2.84s med=12.48s max=16.83s p(90)=13.96s p(95)=14.22s
http_reqs......................: 111 3.320505/s
iteration_duration.............: avg=12.18s min=3.87s med=13.49s max=17.86s p(90)=14.96s p(95)=15.27s
iterations.....................: 111 3.320505/s
vus............................: 2 min=2 max=50
vus_max........................: 50 min=50 max=50
running (33.4s), 00/50 VUs, 111 complete and 0 interrupted iterations
default ✓ [======================================] 50 VUs 20s
요청을 처리하는 평균 시간은 11.15초나 걸리고 최소 소요 시간도 2.84초로 너무 긴 처리 시간이 걸리는 것을 확인할 수 있었습니다.
1차 리팩토링 후 결과
Member 1000명 ImageQuiz 155000개
/\\ |‾‾| /‾‾/ /‾‾/
/\\ / \\ | |/ / / /
/ \\/ \\ | ( / ‾‾\\
/ \\ | |\\ \\ | (‾) |
/ __________ \\ |__| \\__\\ \\_____/ .io
execution: local
script: script.js
output: -
scenarios: (100.00%) 1 scenario, 50 max VUs, 50s max duration (incl. graceful stop):
* default: 50 looping VUs for 20s (gracefulStop: 30s)
data_received..................: 309 kB 13 kB/s
data_sent......................: 99 kB 4.2 kB/s
http_req_blocked...............: avg=3.91ms min=0s med=0s max=33.58ms p(90)=23.54ms p(95)=25.73ms
http_req_connecting............: avg=1.99ms min=0s med=0s max=24.69ms p(90)=13.49ms p(95)=15.27ms
http_req_duration..............: avg=2.81s min=1.15s med=2.83s max=4.68s p(90)=3.2s p(95)=3.6s
{ expected_response:true }...: avg=2.81s min=1.15s med=2.83s max=4.68s p(90)=3.2s p(95)=3.6s
http_req_failed................: 0.00% ✓ 0 ✗ 287
http_req_receiving.............: avg=3.81ms min=0s med=0s max=110.88ms p(90)=1ms p(95)=9.51ms
http_req_sending...............: avg=932.41µs min=0s med=0s max=16.76ms p(90)=1.76ms p(95)=5.04ms
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=2.8s min=1.04s med=2.83s max=4.68s p(90)=3.2s p(95)=3.6s
http_reqs......................: 287 12.140331/s
iteration_duration.............: avg=3.83s min=2.19s med=3.84s max=5.74s p(90)=4.21s p(95)=4.63s
iterations.....................: 287 12.140331/s
vus............................: 13 min=13 max=50
vus_max........................: 50 min=50 max=50
running (23.6s), 00/50 VUs, 287 complete and 0 interrupted iterations
default ✓ [======================================] 50 VUs 20s
요청을 처리하는 평균 시간은 2.81초로 처음 코드에 비해서는 훨씬 좋아졌고 최소 소요 시간도 1.15초로 기존의 코드보다는 좋은 성능이지만 아직 좋지 않은 성능을 보여주고 있습니다.
2차 리팩토링 후 결과
Member 1000명 ImageQuiz 155000개
/\\ |‾‾| /‾‾/ /‾‾/
/\\ / \\ | |/ / / /
/ \\/ \\ | ( / ‾‾\\
/ \\ | |\\ \\ | (‾) |
/ __________ \\ |__| \\__\\ \\_____/ .io
execution: local
script: script.js
output: -
scenarios: (100.00%) 1 scenario, 50 max VUs, 50s max duration (incl. graceful stop):
* default: 50 looping VUs for 20s (gracefulStop: 30s)
data_received..................: 339 kB 15 kB/s
data_sent......................: 109 kB 4.7 kB/s
http_req_blocked...............: avg=2.66ms min=0s med=0s max=30.77ms p(90)=13.03ms p(95)=17.51ms
http_req_connecting............: avg=737.63µs min=0s med=0s max=19.75ms p(90)=2.28ms p(95)=4.78ms
http_req_duration..............: avg=2.42s min=527.09ms med=2.47s max=4.13s p(90)=2.79s p(95)=3.27s
{ expected_response:true }...: avg=2.42s min=527.09ms med=2.47s max=4.13s p(90)=2.79s p(95)=3.27s
http_req_failed................: 0.00% ✓ 0 ✗ 315
http_req_receiving.............: avg=573.97µs min=0s med=0s max=26.91ms p(90)=981.06µs p(95)=1.05ms
http_req_sending...............: avg=360.05µs min=0s med=0s max=36.36ms p(90)=507.38µs p(95)=1ms
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=2.42s min=523.75ms med=2.47s max=4.13s p(90)=2.79s p(95)=3.27s
http_reqs......................: 315 13.608716/s
iteration_duration.............: avg=3.44s min=1.59s med=3.49s max=5.15s p(90)=3.83s p(95)=4.31s
iterations.....................: 315 13.608716/s
vus............................: 7 min=7 max=50
vus_max........................: 50 min=50 max=50
running (23.1s), 00/50 VUs, 315 complete and 0 interrupted iterations
default ✓ [======================================] 50 VUs 20s
요청을 처리하는 평균 시간은 2.42초, 최소 소요 시간도 527.09ms로 평균 소요 시간은 1차 리팩토링 결과와 큰 차이가 없지만 최소 소요 시간이 더 작아진 것을 확인하실 수 있습니다.
위와 같은 결과가 나오는 이유는 1차 리팩토링을 했을 때는 ORDER BY RAND()를 사용하여 항상 비슷한 시간이 걸리지만 2차 리팩토링 후의 결과는 offset에 따라서 걸리는 시간의 편차가 존재하기 때문입니다.
2차 리팩토링 후의 결과를 optimizer로 분석한 결과는 아래와 같습니다. 분석을 위해서 explain analysis 함수를 사용하였습니다.
count query explain
-> Aggregate: count(0) (cost=31126 rows=1) (actual time=67.5..67.5 rows=1 loops=1)
-> Filter: ((iq1_0.is_default = 1) or (iq1_0.member_id = 5)) (cost=15759 rows=153664) (actual time=0.0482..62.2 rows=135000 loops=1)
-> Table scan on iq1_0 (cost=15759 rows=153664) (actual time=0.0464..48.4 rows=155000 loops=1)
소모 예상 시간 : 67.5ms
실제 조회 쿼리 explain
-> Limit: 5 row(s) (cost=15714 rows=5) (actual time=160..160 rows=5 loops=1)
-> Sort: iq.rand_val, limit input to 5 row(s) per chunk (cost=15714 rows=153369) (actual time=160..160 rows=5 loops=1)
-> Filter: ((iq.is_default = true) or (iq.member_id = 5)) (cost=15714 rows=153369) (actual time=0.0701..132 rows=135040 loops=1)
-> Table scan on iq (cost=15714 rows=153369) (actual time=0.0681..116 rows=155000 loops=1)
소모 예상 시간 : 160ms
이 분석 결과를 보고 count의 비용이 생각보다 크다는 것을 확인할 수 있었고 이를 줄이기 위해서 Map에 count의 결과를 보관하게 하였습니다.
3차 리팩토링 후 결과
Member 1000명 ImageQuiz 155000개
/\ |‾‾| /‾‾/ /‾‾/
/\ / \ | |/ / / /
/ \/ \ | ( / ‾‾\
/ \ | |\ \ | (‾) |
/ __________ \ |__| \__\ \_____/ .io
execution: local
script: script.js
output: -
scenarios: (100.00%) 1 scenario, 50 max VUs, 50s max duration (incl. graceful stop):
* default: 50 looping VUs for 20s (gracefulStop: 30s)
data_received..................: 1.0 MB 48 kB/s
data_sent......................: 325 kB 16 kB/s
http_req_blocked...............: avg=971.34µs min=0s med=0s max=23ms p(90)=0s p(95)=16.67ms
http_req_connecting............: avg=103.43µs min=0s med=0s max=6.29ms p(90)=0s p(95)=526.67µs
http_req_duration..............: avg=82.49ms min=7.58ms med=49.53ms max=786.1ms p(90)=133.05ms p(95)=339.1ms
{ expected_response:true }...: avg=82.49ms min=7.58ms med=49.53ms max=786.1ms p(90)=133.05ms p(95)=339.1ms
http_req_failed................: 0.00% ✓ 0 ✗ 938
http_req_receiving.............: avg=844.84µs min=0s med=371.1µs max=121.94ms p(90)=998.73µs p(95)=1.02ms
http_req_sending...............: avg=61.9µs min=0s med=0s max=4.14ms p(90)=0s p(95)=454.24µs
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=81.58ms min=7.5ms med=49.05ms max=785.03ms p(90)=130.87ms p(95)=338.01ms
http_reqs......................: 938 44.712357/s
iteration_duration.............: avg=1.09s min=1.01s med=1.05s max=1.83s p(90)=1.15s p(95)=1.37s
iterations.....................: 938 44.712357/s
vus............................: 50 min=50 max=50
vus_max........................: 50 min=50 max=50
running (21.0s), 00/50 VUs, 938 complete and 0 interrupted iterations
default ✓ [======================================] 50 VUs 20s요청을 처리하는 평균 시간은 82.49ms, 최소 소요 시간 7.58ms로 성능이 훨씬 좋아짐을 확인하실 수 있습니다.
위와 같은 결과가 나오는 이유는 rand_val column에 non-clustered index를 설정하여 order by에서 정렬할 때 성능을 많이 향상하고 covering index로 불필요한 비용을 없앴기 때문입니다.
아래의 코드를 활용하여 optimizer는 얼마의 시간이 걸릴지 확인해 보았습니다.
상황은 155000개의 문제가 있을 때 관리자가 등록한 문제 + 유저가 등록한 문제가 20000개라고 가정하고 그 중앙값인 10000에 해당하는 부분부터 5개의 문제를 가져온다고 가정하였습니다.
explain analyze
select iq.quiz_id, iq.answer, iq.s3_url
FROM image_quiz iq
WHERE iq.is_default = TRUE OR iq.member_id = 5
ORDER BY iq.rand_val LIMIT 5 OFFSET 10000;위에 대한 분석 결과는 아래와 같습니다. covering index이 제대로 적용된 것을 확인할 수 있습니다.
-> Limit/Offset: 5/10000 row(s) (cost=616 rows=0) (actual time=5.48..5.48 rows=5 loops=1)
-> Filter: ((iq.is_default = true) or (iq.member_id = 5)) (cost=616 rows=5503) (actual time=0.0642..5.18 rows=10005 loops=1)
-> Covering index scan on iq using idx_image_quiz_rand_val (cost=616 rows=10005) (actual time=0.0624..4.4 rows=11463 loops=1)이를 좀 더 자세하게 보기 위해서 explain format = json으로 분석을 하겠습니다.
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "15712.30"
},
"ordering_operation": {
"using_filesort": false,
"table": {
"table_name": "iq",
"access_type": "index",
"possible_keys": [
"FKnb7286m4bfjkj1ftnn813ou53"
],
"key": "idx_image_quiz_rand_val",
"used_key_parts": [
"rand_val",
"is_default",
"member_id",
"answer",
"s3_url"
],
"key_length": "906",
"rows_examined_per_scan": 10005,
"rows_produced_per_join": 76746,
"filtered": "55.00",
"using_index": true,
"cost_info": {
"read_cost": "8037.66",
"eval_cost": "7674.64",
"prefix_cost": "15712.30",
"data_read_per_join": "163M"
},
"used_columns": [
"is_default",
"member_id",
"quiz_id",
"rand_val",
"answer",
"s3_url"
],
"attached_condition": "((`kidbeandb`.`iq`.`is_default` = true) or (`kidbeandb`.`iq`.`member_id` = 5))"
}
}
}
}위의 분석 결과를 확인하면 index를 잘 사용하고 있고, used_key_parts를 보시면 covering index를 모두 다 활용하여 성능을 최적화시킨 모습을 확인할 수 있습니다.
마지막으로 데이터의 개수에 따른 소요 시간을 한눈에 볼 수 있게 그래프로 그려보겠습니다.
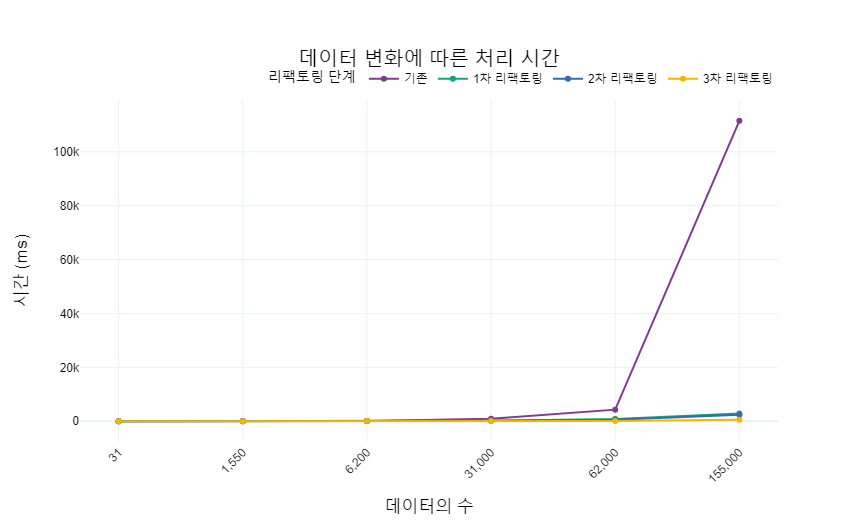
기존 코드의 성능이 굉장히 좋지 않아 다른 코드들의 차이가 적어 보이니 기존 코드를 빼고 성능을 보도록 하겠습니다.

리팩토링이 진행되면서 점점 성능이 향상되었고 마지막에 가서는 데이터가 적을 때, 많을 때 모두 이전보다 훨씬 좋은 성능을 보이는 것을 확인할 수 있습니다.
데이터가 많아질수록 리팩토링 후의 코드가 더 성능이 좋아지는 것을 쉽게 확인하실 수 있습니다.
'CS > 스프링' 카테고리의 다른 글
| synchnonized, 비관적 락, 낙관적 락, 분산락(named lock)을 사용한 데드락 처리 (0) | 2024.07.26 |
|---|---|
| QueryDSL을 활용한 동적 쿼리 처리 (0) | 2024.07.17 |
| spring 프로젝트에서 더미 데이터 사용 & 테스트용 fixture 사용하기 (1) | 2024.06.16 |
| spring security 적용시 @WebMvcTest 코드에서 csrf() 없애기 (0) | 2024.06.06 |
| N + 1 문제와 해결 방법 (1) | 2024.02.14 |



댓글