이번 게시글에서는 무한 페이징 기능을 구현하면서 나온 문제 상황을 해결해 보도록 하겠습니다.
프로젝트를 진행하면서 페이징 기능을 구현하면서 페이징을 진행할 때 중복된 데이터가 나오는 상황이 발생하였습니다.
해당 상황은 게시글에 달린 리뷰를 최신순으로 가져와 사용자에게 보여주는데 A 유저가 페이징을 진행하던 중 중간에 잠시 멈추고 B 유저가 새로운 리뷰를 달았을 때 A 유저가 다시 페이징을 진행하면 이전에 확인한 데이터가 다시 보여진다는 것이었습니다.
이 상황이 발생하는 이유는 offset을 사용하여 paging을 진행하고 있었기 때문입니다. offset을 사용하면 문제가 발생하는 이유는 아래와 같습니다.

위 사진에서는 page의 크기가 5라고 지정하였습니다. 이때 A 유저가 계속 페이징을 진행하는 상황에서 B 유저가 새로운 리뷰를 작성한다면 offset 기반의 페이징을 진행할 때는 조건에 맞게 정렬 후 가장 처음 row부터 차례대로 offset을 진행한 후 마지막에 limit로 필요한 만큼의 데이터를 가져오기 때문에 B 유저가 등록한 101번 id의 리뷰 때문에 중복된 데이터를 가져오게 됩니다.
위 상황을 해결하기 위해서 저는 offset 기반의 페이징이 아니라 cursor의 개념을 이용하기로 했습니다. 이를 활용하기 위하여 유저에게 마지막으로 본 id를 다시 서버로 보내게 만들어 새로운 리뷰가 추가되더라도 위와 같은 문제가 발생하지 않게 했습니다.

위와 같이 이전에 마지막으로 본 review의 id를 받아서 where 절에서 이를 미리 제거한다면 중간에 새로운 데이터가 추가되더라고 크게 문제가 없을 것입니다.
이 방식은 offset을 사용하는 것과 비교하여 성능상으로도 장점이 있습니다.
select 쿼리는 from -> where -> group by -> having -> order by -> select와 같은 실행 순서를 지니고 있습니다. 이때 offset이 작동하는 순서도 where 다음입니다.
offset의 작동 원리는 만약 offset 50 limit 5와 같은 조건이 있다면 50개의 row를 읽은 후 버리고 이후 5개의 row를 가져오는데 이때 50개의 row를 다 읽어야 하니 이 비용이 발생하게 됩니다. 이때 where을 이용하여 미리 50개의 row를 없애고 limit 5만 해준다면 이러한 비용 또한 없앨 수 있어 성능상으로도 더 좋아지게 됩니다.
우선 위와 같은 방식으로 구현된 코드를 보여드린 후 마지막으로 성능 차이를 확인해보도록 하겠습니다.
Controller
@GetMapping("/{placeId}")
public ResponseEntity<ResponseTemplate<?>> getReviewList(
@PathVariable Long placeId,
@RequestParam Long lastReviewId,
@RequestParam(defaultValue = "5") Long size) {
ReviewSimpleResponseList reviewSimpleResponse =
reviewService.getReviewSimpleResponse(placeId, lastReviewId, size);
return ResponseEntity
.status(HttpStatus.OK)
.body(ResponseTemplate.from(reviewSimpleResponse));
}Service
@Transactional(readOnly = true)
public ReviewSimpleResponseList getReviewSimpleResponse(Long placeId, Long lastReviewId, Long size) {
List<ReviewSimpleResponse> reviewSimpleResponse =
reviewRepository.getReviewSimpleResponse(placeId, lastReviewId, size);
Boolean hasNext = reviewRepository.hasNext(placeId, lastReviewId, size);
return ReviewSimpleResponseList.of(hasNext, reviewSimpleResponse);
}Repository
@Override
public List<ReviewSimpleResponse> getReviewSimpleResponse(Long placeId, Long lastReviewId, Long size) {
return jpaQueryFactory.select(
Projections.constructor(ReviewSimpleResponse.class,
review.id,
review.user.nickname,
review.content,
review.rating,
review.date,
review.reviewImageUrl
)
)
.from(review)
.where(review.place.id.eq(placeId), review.id.lt(lastReviewId)) // lastReviewId를 기준으로 필터링
.orderBy(review.id.desc())
.limit(size) // 가져올 리뷰 수 제한
.fetch();
}
@Override
public Boolean hasNext(Long placeId, Long lastReviewId, Long size) {
return jpaQueryFactory.selectOne()
.from(review)
.where(review.place.id.eq(placeId), review.id.lt(lastReviewId - size))
.fetchFirst() != null;
}DTO
public record ReviewSimpleResponse(
Long reviewId,
String writer,
String content,
BigDecimal rating,
@JsonFormat(pattern = "yyyy-MM-dd")
LocalDateTime date,
String reviewImageUrl
) {
@JsonProperty("reviewImageUrl")
public String getFormattedImageUrl() {
return reviewImageUrl == null ? "" : reviewImageUrl;
}
}DTO List
public record ReviewSimpleResponseList(
Boolean hasNext,
List<ReviewSimpleResponse> reviewSimpleResponseList
) {
public static ReviewSimpleResponseList of(Boolean hasNext, List<ReviewSimpleResponse> reviewSimpleResponseList) {
return new ReviewSimpleResponseList(hasNext, reviewSimpleResponseList);
}
}no offset 무한 페이징을 위한 코드는 위와 같습니다.
가장 최근 리뷰를 확인하는 부분은 게시글을 누를 때 함께 넘어가기 때문에 lastReviewId가 0일 때와 같이 처음 페이징을 진행할 때의 조건은 추가하지 않았습니다.
Repository는 queryDSL을 사용하여 컴파일 시점에 SQL 구문이 문제가 있는지 확인 및 SQL 자체의 작성을 편하게 하였습니다.
또한 hasNext는 다음 페이지에 데이터가 있는지를 보여주고 있는데 이를 위해서 count 쿼리가 한번 더 나가게 됩니다. 이와 같이 Query가 한번 더 발생하는 것은 불필요한 비용이 드는 작업입니다.
이 문제에 대해서도 개선을 진행해보도록 하겠습니다.
성능을 개선하기 위해서 아래와 같이 limit에서 size + 1 개의 데이터를 가져오게 만들었습니다. 이렇게 한 후 service에서 원소의 개수가 size가 이하이면 다음 페이지가 없는 것으로 판단하게 만들어 쿼리의 수를 줄일 수 있었습니다.
Repository
public List<ReviewSimpleResponse> getReviewSimpleResponse(Long placeId, Long lastReviewId, Long size) {
return jpaQueryFactory.select(
Projections.constructor(ReviewSimpleResponse.class,
review.id,
review.user.nickname,
review.content,
review.rating,
review.date,
review.reviewImageUrl
)
)
.from(review)
.where(review.place.id.eq(placeId), review.id.lt(lastReviewId)) // lastReviewId를 기준으로 필터링
.orderBy(review.id.desc())
.limit(size + 1) // 가져올 리뷰 수 제한
.fetch();
}Service
public ReviewSimpleResponseList getReviewSimpleResponse(Long placeId, Long lastReviewId, Long size) {
List<ReviewSimpleResponse> reviewSimpleResponseList =
reviewRepository.getReviewSimpleResponse(placeId, lastReviewId, size);
boolean hasNext = reviewSimpleResponseList.size() == size + 1;
// 마지막 원소를 제외한 서브 리스트 생성
if (hasNext) {
reviewSimpleResponseList = reviewSimpleResponseList.subList(0, reviewSimpleResponseList.size() - 1);
}
return ReviewSimpleResponseList.of(hasNext, reviewSimpleResponseList);
}마지막으로 발생 쿼리의 실행 계획을 분석하여 실행 시간을 비교해보도록 하겠습니다.
성능 비교는 순수히 offset을 사용했냐, where로 lastReviewId에 대한 조건을 사용했냐로만 진행하도록 하겠습니다.
데이터는 100,000개를 넣어서 진행하였고 테스트에 사용한 쿼리는 아래와 같습니다. 아래의 쿼리에서 수를 바꿔가며 테스트를 진행하도록 하겠습니다.
explain analyze
select *
from review
limit 5 offset 10;
explain analyze
select *
from review
where id > 10
limit 5;Offset 10
offset 실행 계획
-> Limit/Offset: 5/10 row(s) (cost=10103 rows=5) (actual time=0.0666..0.0675 rows=5 loops=1)
-> Table scan on review (cost=10103 rows=99828) (actual time=0.0632..0.0656 rows=15 loops=1)where 실행 계획
-> Limit: 5 row(s) (cost=10008 rows=5) (actual time=0.0172..0.0263 rows=5 loops=1)
-> Filter: (review.id > 10) (cost=10008 rows=49914) (actual time=0.0164..0.0252 rows=5 loops=1)
-> Index range scan on review using PRIMARY over (10 < id) (cost=10008 rows=49914) (actual time=0.0152..0.0238 rows=5 loops=1)위의 실행 계획을 보시면 offset을 사용하면 모든 row를 읽은 후 제외해야 하기 때문에 table scan을 사용하고 where은 Primary Key에 대한 index가 설정되어 있기 때문에 이를 사용하는 것을 확인하실 수 있습니다.
Offset 1000
offset 실행 계획
-> Limit/Offset: 5/1000 row(s) (cost=10103 rows=5) (actual time=0.906..0.908 rows=5 loops=1)
-> Table scan on review (cost=10103 rows=99828) (actual time=0.0896..0.873 rows=1005 loops=1)where 실행 계획
-> Limit: 5 row(s) (cost=10008 rows=5) (actual time=0.0166..0.0258 rows=5 loops=1)
-> Filter: (review.id > 1000) (cost=10008 rows=49914) (actual time=0.0157..0.0245 rows=5 loops=1)
-> Index range scan on review using PRIMARY over (1000 < id) (cost=10008 rows=49914) (actual time=0.0146..0.0231 rows=5 loops=1)offset이 커질수록 점점 차이가 발생하는 것을 확인 가능합니다.
Offset 10000
offset 실행 계획
-> Limit/Offset: 5/10000 row(s) (cost=10103 rows=5) (actual time=7.78..7.79 rows=5 loops=1)
-> Table scan on review (cost=10103 rows=99828) (actual time=0.115..7.29 rows=10005 loops=1)where 실행 계획
-> Limit: 5 row(s) (cost=10008 rows=5) (actual time=0.02..0.0396 rows=5 loops=1)
-> Filter: (review.id > 10000) (cost=10008 rows=49914) (actual time=0.0194..0.0387 rows=5 loops=1)
-> Index range scan on review using PRIMARY over (10000 < id) (cost=10008 rows=49914) (actual time=0.0177..0.0367 rows=5 loops=1)offset이 커질수록 점점 차이가 발생하는 것을 확인 가능합니다.
Offset 30000
offset 실행 계획
-> Limit/Offset: 5/30000 row(s) (cost=10103 rows=5) (actual time=14..14 rows=5 loops=1)
-> Table scan on review (cost=10103 rows=99828) (actual time=0.0615..13.3 rows=30005 loops=1)where 실행 계획
-> Limit: 5 row(s) (cost=10008 rows=5) (actual time=0.0249..0.0354 rows=5 loops=1)
-> Filter: (review.id > 30000) (cost=10008 rows=49914) (actual time=0.0242..0.0345 rows=5 loops=1)
-> Index range scan on review using PRIMARY over (30000 < id) (cost=10008 rows=49914) (actual time=0.022..0.0321 rows=5 loops=1)Offset 50000
offset 실행 계획
-> Limit/Offset: 5/50000 row(s) (cost=10103 rows=5) (actual time=27.8..27.8 rows=5 loops=1)
-> Table scan on review (cost=10103 rows=99828) (actual time=0.0441..25.5 rows=50005 loops=1)where 실행 계획
-> Limit: 5 row(s) (cost=10008 rows=5) (actual time=0.0171..0.026 rows=5 loops=1)
-> Filter: (review.id > 50000) (cost=10008 rows=49914) (actual time=0.0163..0.025 rows=5 loops=1)
-> Index range scan on review using PRIMARY over (50000 < id) (cost=10008 rows=49914) (actual time=0.0149..0.0234 rows=5 loops=1)Offset 100000
offset 실행 계획
-> Limit/Offset: 5/100000 row(s) (cost=10103 rows=0) (actual time=56.8..56.8 rows=0 loops=1)
-> Table scan on review (cost=10103 rows=99828) (actual time=0.0475..53 rows=100000 loops=1)where 실행 계획
-> Limit: 5 row(s) (cost=0.46 rows=1) (actual time=0.0167..0.0167 rows=0 loops=1)
-> Filter: (review.id > 100000) (cost=0.46 rows=1) (actual time=0.016..0.016 rows=0 loops=1)
-> Index range scan on review using PRIMARY over (100000 < id) (cost=0.46 rows=1) (actual time=0.0153..0.0153 rows=0 loops=1)위의 결과들을 그래프로 정리해보도록 하겠습니다.
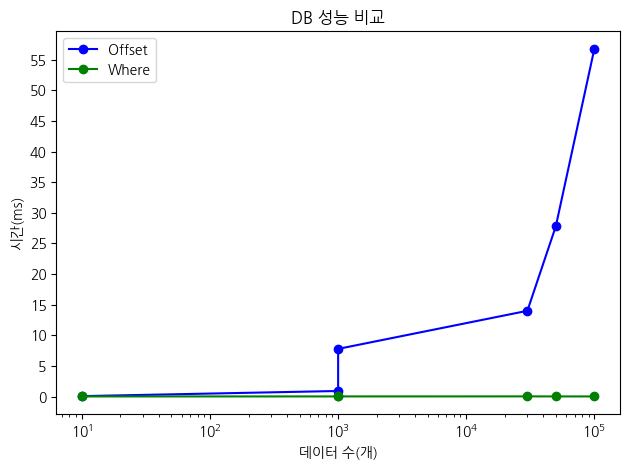
offset을 사용하면 데이터의 수가 늘수록 성능이 급격하게 안 좋아지는 반면, where을 사용하면 항상 안정적인 성능을 보이는 것을 확인할 수 있었습니다.
'CS > 스프링' 카테고리의 다른 글
| SpringBoot와 Clova Studio를 활용한 RAG 구현 (5) | 2024.12.03 |
|---|---|
| AOP를 이용한 분산락(Named Lock) 처리 (0) | 2024.07.28 |
| synchnonized, 비관적 락, 낙관적 락, 분산락(named lock)을 사용한 데드락 처리 (0) | 2024.07.26 |
| QueryDSL을 활용한 동적 쿼리 처리 (0) | 2024.07.17 |
| join 제거, dto projection, covering index를 활용한 성능 최적화 (1) | 2024.07.04 |




댓글