
이 문제는 스택 구조를 이용한 문제로 아래의 문제인 오큰수와 유사한 문제입니다.
이 문제를 풀기 전에 아래의 문제를 보고 오시는게 좋을 겁니다.
백준 17298번 : 오큰수 java
이 문제는 자료구조 중에서 스택을 이용하여 푸는 문제입니다. 이 문제를 풀 때 해당 인덱스의 수보다 오른쪽에 있으면서 해당 수보다 큰 수 중에서 가장 왼쪽에 있는 수를 찾으면 됩니다. 이를
dy-coding.tistory.com
이 문제에서는 수가 배열에 몇 개가 들어있냐를 기준으로 수를 집어넣습니다.
입력된 자료들을 순회하며 데이터들이 몇 개씩 있는지를 확인한 후 조건에 맞게 정답 배열을 채웁니다.
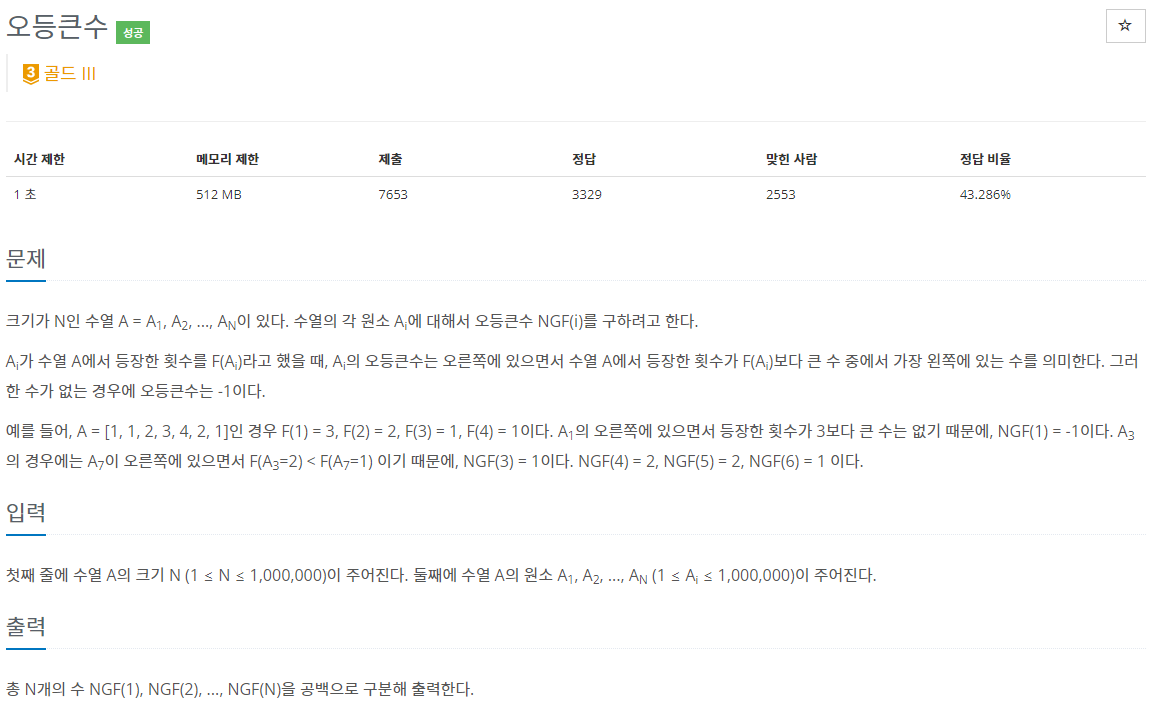
위의 그림은 위 문제의 예제 1번을 나타낸 그림입니다.
data의 개수들은 count배열에 넣었습니다.
이제 stack에 data들을 하나씩 넣으면서 문제의 조건에 맞게 answer을 작성해보겠습니다.
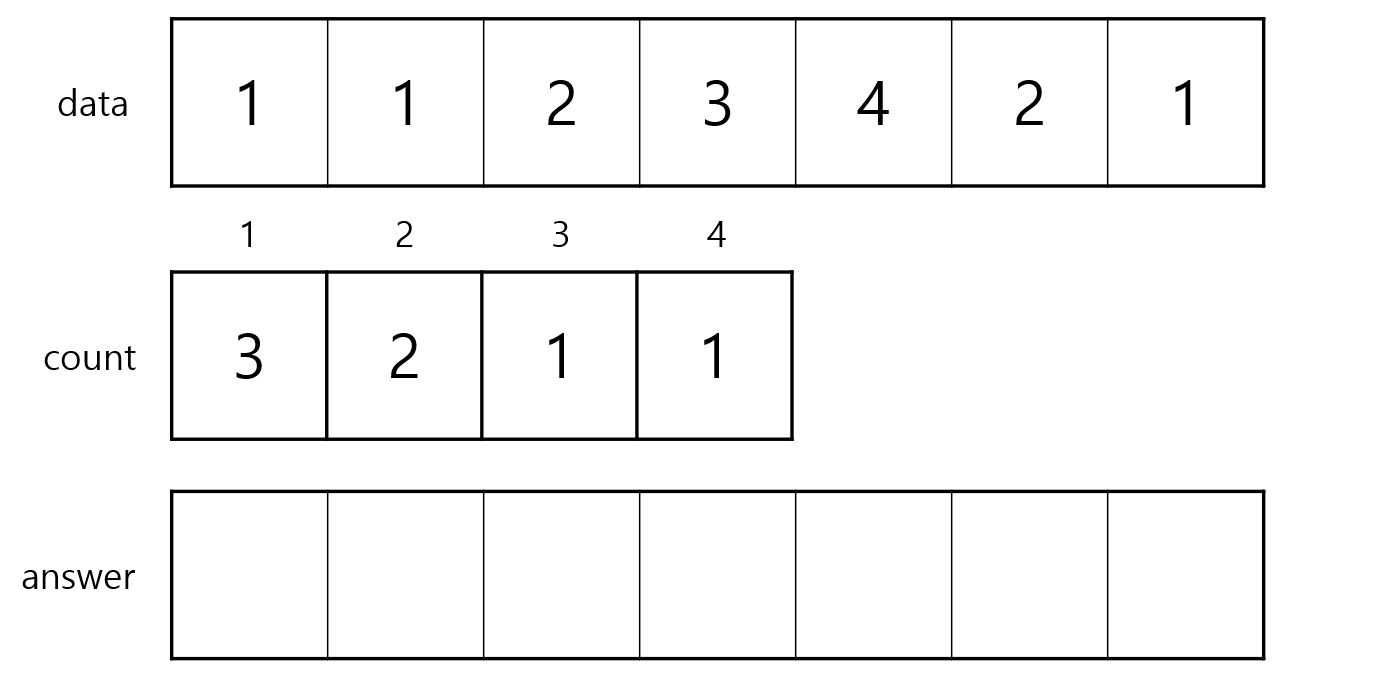
위의 그림과 같이 stack에는 data의 index를 넣습니다.
0번 index일 때는 stack안에 비교할 값이 없기 때문에 그래서 0을 stack에 add해줍니다.
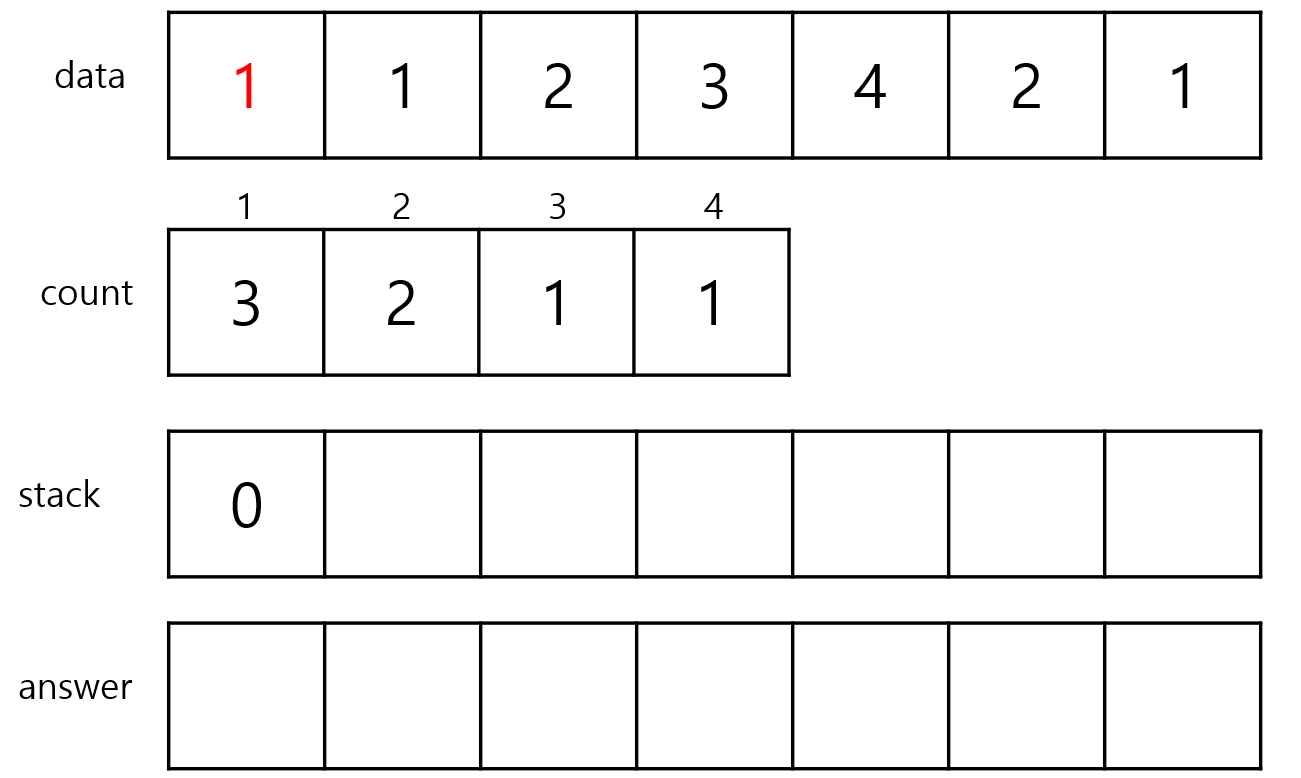
1번 index를 stack에 있는 index의 count와 비교하면 0번 index는 count 3이고 1번 index도 같기 때문에 stack에 있는 값을 pop하지 않고 1을 add해줍니다.
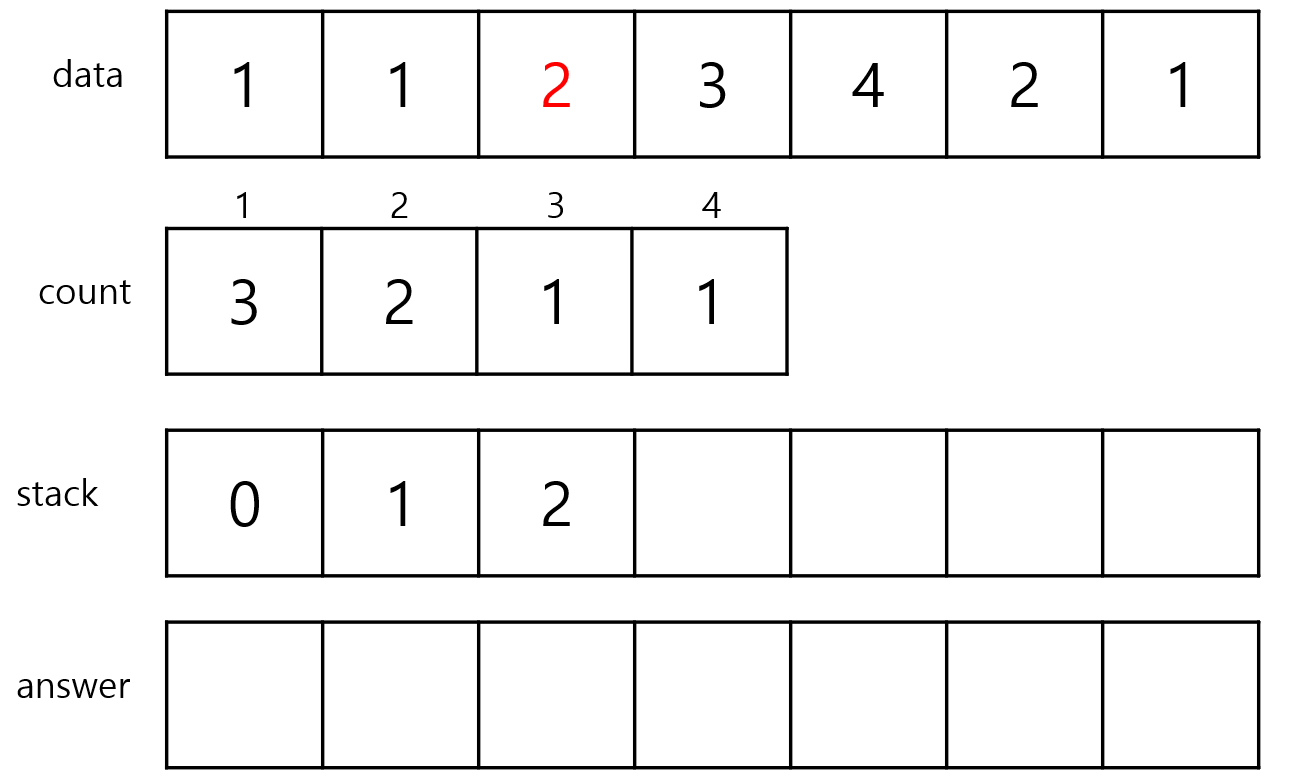
2번 index를 stack에 있는 index들의 count와 비교하면 2번 index의 count는 count[2]인 2인데 stack 안에 있는 index들의 count들은 count[1]인 3이므로 새로 들어온 index의 count가 더 작기 때문에 stack을 pop하지 않고 add해줍니다.
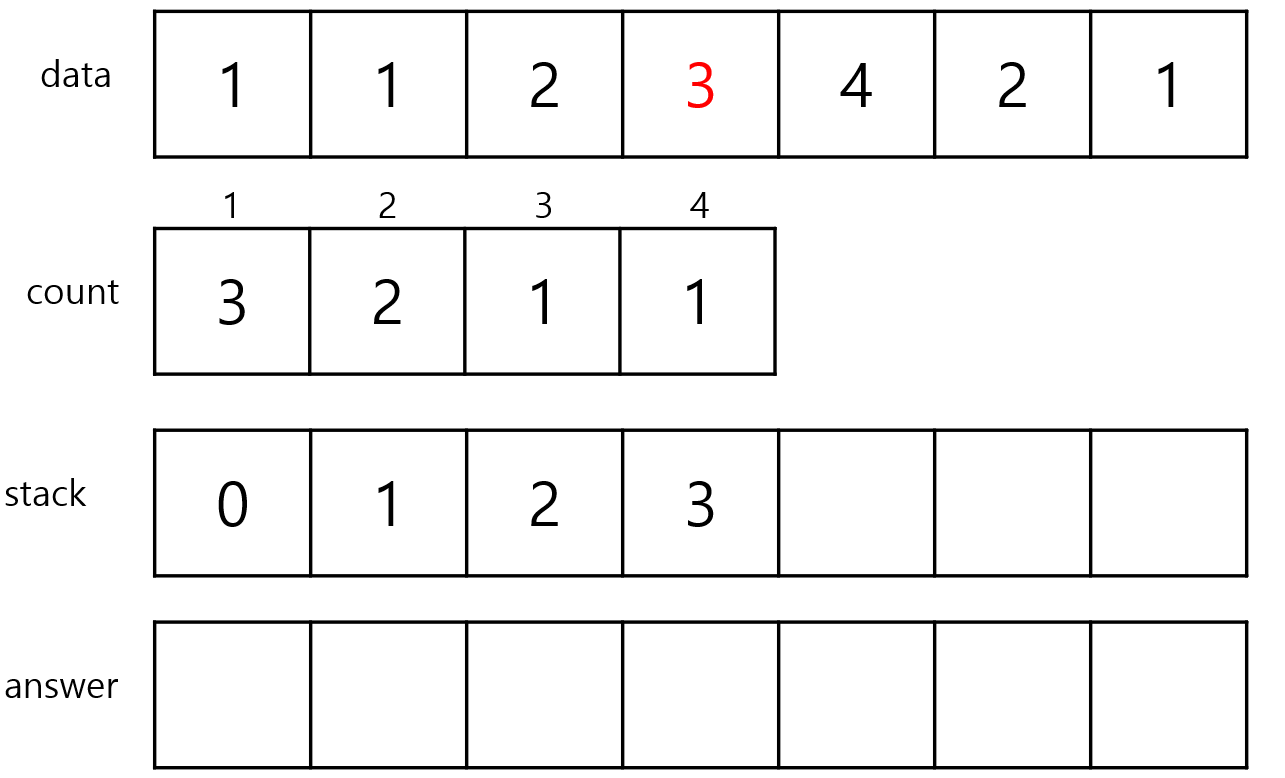
3번 index가 stack에 추가될 때도 이전에 있던 index들의 count보다 작기 때문에 stack에 그냥 추가해줍니다.
4번 index가 stack에 추가될 때도 이와 같습니다.
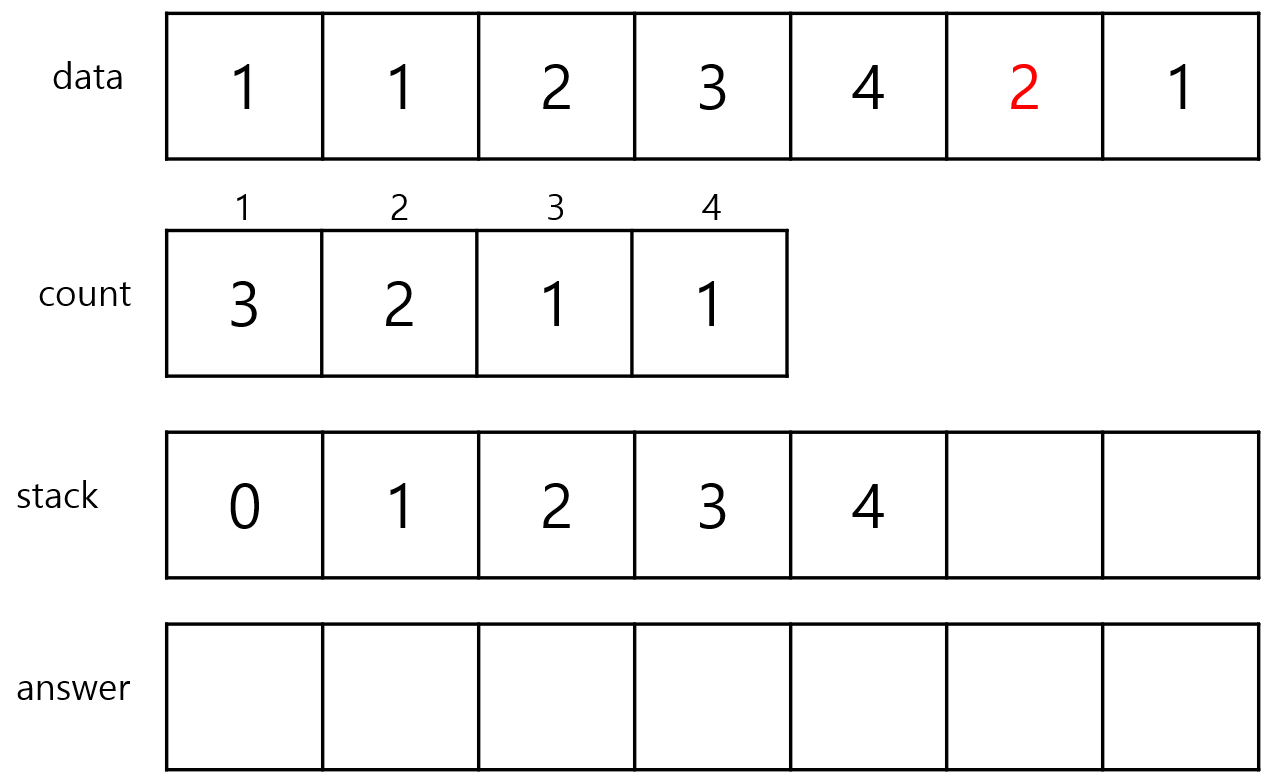
이제 5번 index가 들어올 때는 상황이 조금 다릅니다.
5번 index의 값은 2로 count[2]를 보시면 2의 값을 가지고 있습니다.
그런데 stack을 peek한 값은 4입니다.
4번 index의 data는 4입니다.
data 4의 count는 count[4] == 1이므로 새로 들어오는 index의 count보다 작습니다.
따라서 4번 index를 pop해주고 answer[4]의 값을 새로 들어온 index 5의 data값인 2로 바꿔줍니다.
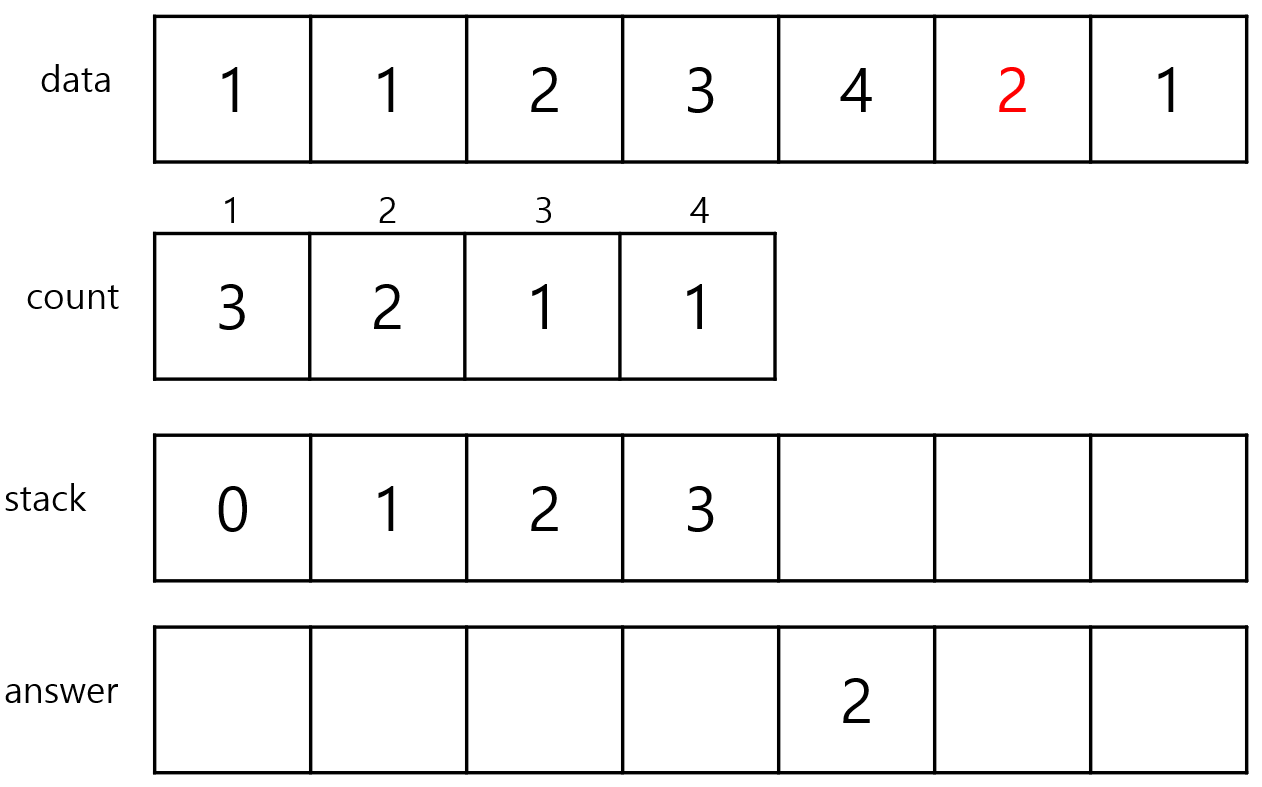
이어서 다시 stack을 peek해보면 index 3이 있습니다.
index가 3일 때의 data는 3이고 count는 1이므로 위의 과정을 반복합니다.
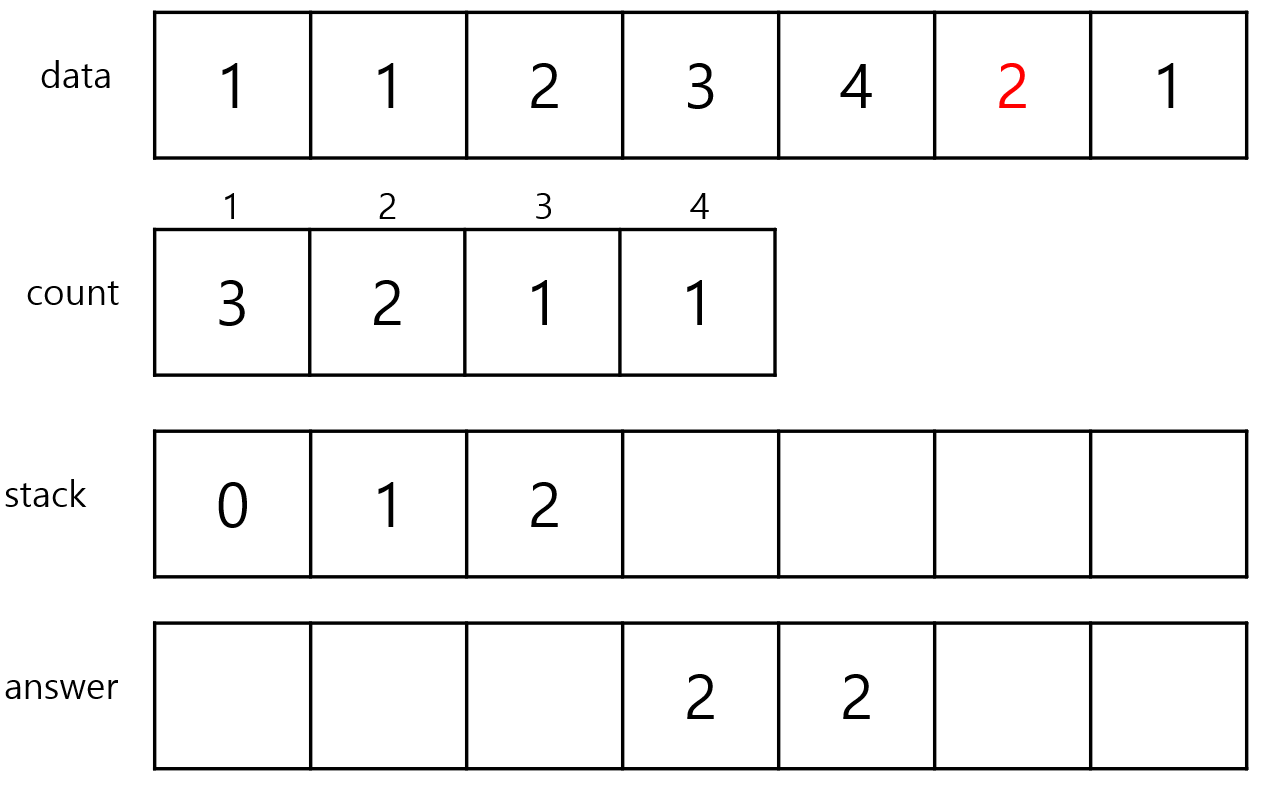
다시 stack을 peek해보면 index가 2입니다.
index 2에 들어있는 값은 2이기 때문에 새로 들어온 index 5의 data 2의 count와 같습니다.
따라서 index 5를 stack에 add해줍니다.
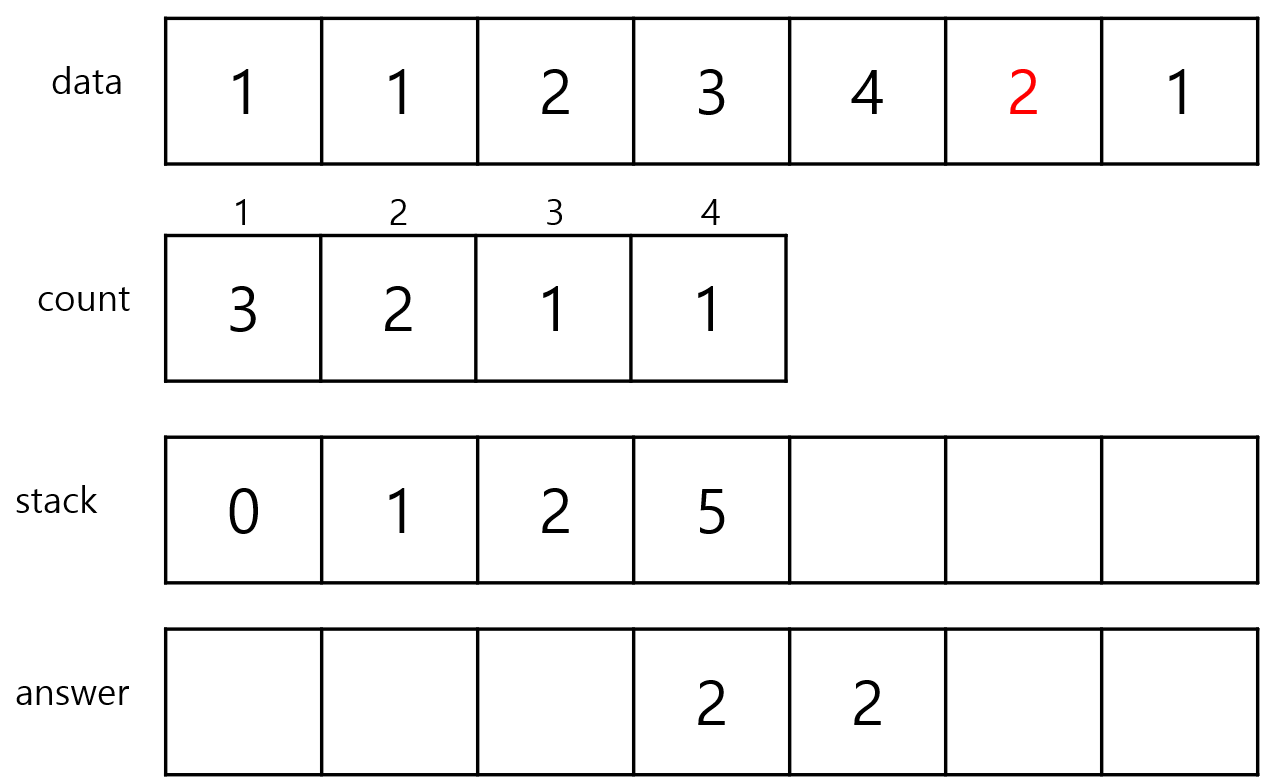
index 6이 들어올 때는 data의 값이 1이고 count는 1이기 때문에 이전에 있던 값들 중에서 count가 1, 2인 index들을
pop할 수 있습니다.
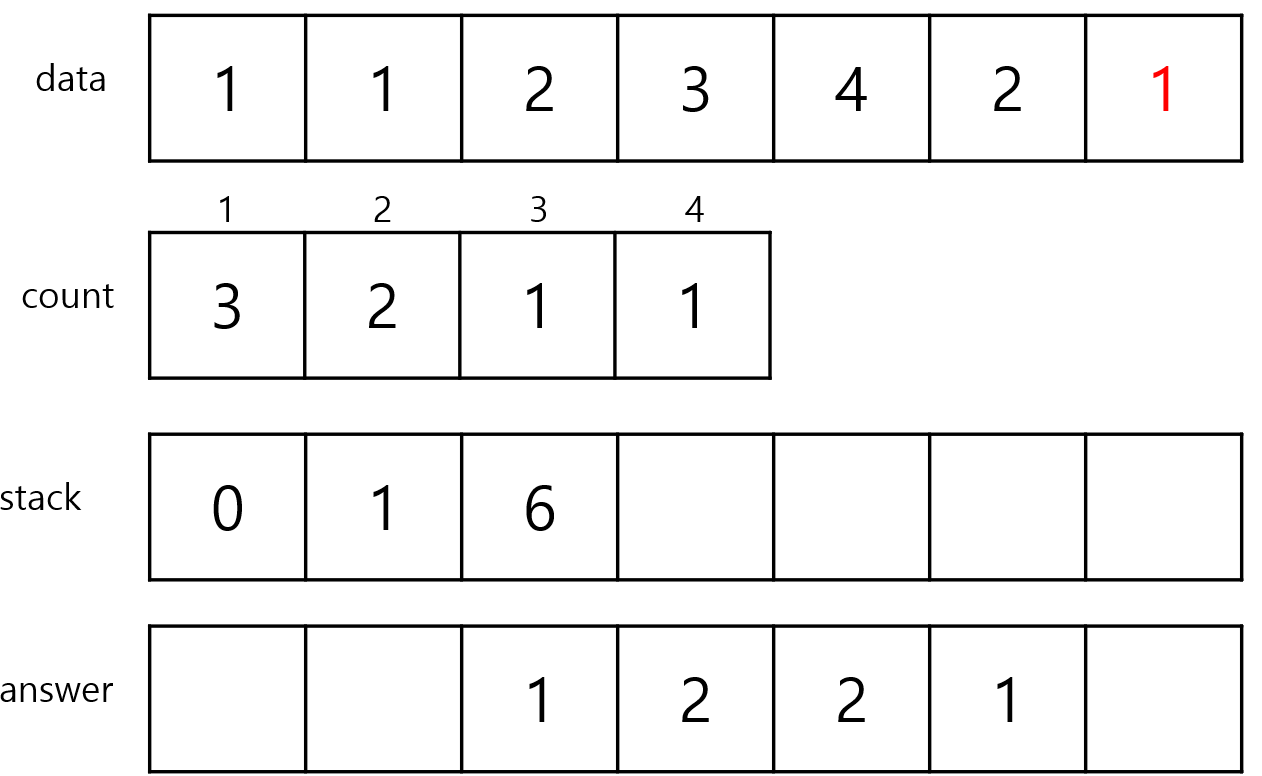
stack안에 있는 index 중에서 5번 index, 2번 index는 data가 2이고 count는 2이기 때문에 pop해줍니다.
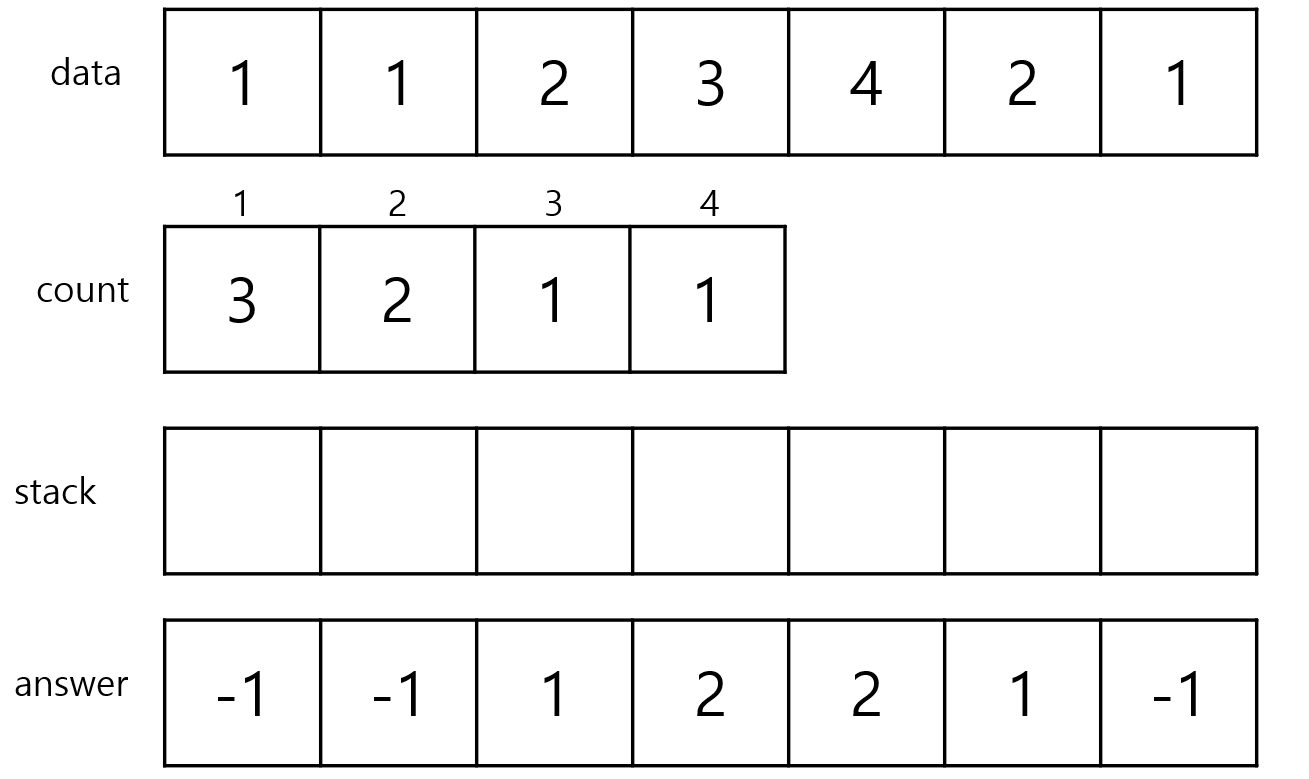
이제 새로 들어오는 data가 없기 때문에 오등큰수를 찾을 수 없어 stack에 남아있는 index들의 answer을 -1로
초기화해줍니다.
이와 같은 과정으로 문제를 해결하실 수 있습니다.
import java.io.*;
import java.util.*;
public class Main {
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuffer sb = new StringBuffer();
int N = Integer.parseInt(br.readLine());
int[] data = new int[N];
int[] cnt = new int[1_000_001];
int[] answer = new int[N];
StringTokenizer st = new StringTokenizer(br.readLine());
for(int i = 0; i<N; i++) {
data[i] = Integer.parseInt(st.nextToken());
cnt[data[i]]++;
}
Stack<Integer> s = new Stack<>();
for(int i = 0; i<N; i++){
while(!s.isEmpty() && cnt[data[s.peek()]]<cnt[data[i]]){
answer[s.pop()] = data[i];
}
s.add(i);
}
while(!s.isEmpty())
answer[s.pop()] = -1;
for(int i = 0; i<N; i++)
sb.append(answer[i]).append(" ");
System.out.println(sb);
}
}위 코드 중에서 cnt를 1,000,001개의 공간으로 선언해준 이유는 data의 입력을 다 받은 후 안에 있는 data들의 개수들을 확인하여 cnt를 만들려 하면 시간 초과가 나오기 때문입니다.
for(int i = 0; i<N; i++)
data[i] = Integer.parseInt(st.nextToken());
for(int i = 0; i<N; i++){
if(visited[i])
continue;
Stack<Integer> s = new Stack<>();
for(int j = i; j<N; j++){
if(data[i] == data[j]) {
s.add(j);
visited[j] = true;
}
}
int num = s.size();
while(!s.isEmpty())
cnt[s.pop()] = num;
}위의 코드는 입력을 다 받은 후 cnt를 만드는 부분인데 이와 같이 코딩하시면 2중 반복문을 돌기 때문에 시간 복잡도가 O(N^2)이 되어서 시간 초과가 나옵니다.
'알고리즘 > 자료구조' 카테고리의 다른 글
| 백준 1021번 : 회전하는 큐 java (1) | 2022.06.15 |
|---|---|
| 백준 1158번 : 요세푸스 문제 java (1) | 2022.06.14 |
| 백준 1197번 : 최소 스패닝 트리 java (1) | 2022.06.14 |
| 백준 17298번 : 오큰수 java (3) | 2022.06.13 |
| 백준 11286번 : 절댓값 힙 java (0) | 2022.05.26 |




댓글