

이 문제는 허프만 알고리즘을 이용하여 푸는 문제입니다.
허프만 알고리즘에 대하여 우선 설명드리도록 하겠습니다.
허프만 알고리즘이란 압축 단위마다 문자의 출현 빈도를 조사하여 빈도가 높은 순서대로 비트 수가 적은 부호를 부여함으로써 데이터를 압축하는 방식입니다.
간단히 말하면 많이 사용된 문자는 더 적은 비트로 나타내고 적게 사용된 문자는 더 많은 비트를 사용하여 나타내어 효율적으로 문자열을 나타내겠다는 것입니다.
문자열 하나를 예시로 이에 대해 설명해드리겠습니다.
AAAAAABBBBCDD라는 문자열이 있습니다.
이 문자열에서 A는 6개, B는 4개, C는 1개 D는 2개가 사용되었습니다.
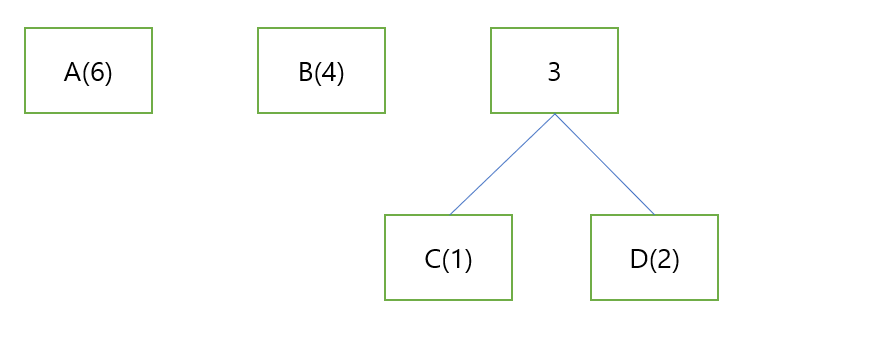
이를 그림으로 나타내면 아래와 같습니다.

허프만 알고리즘을 이용하기 위해서는 가장 적은 사용 빈도를 가진 두 항을 묶고 그 합을 아래의 그림과 같이 적어줍니다.
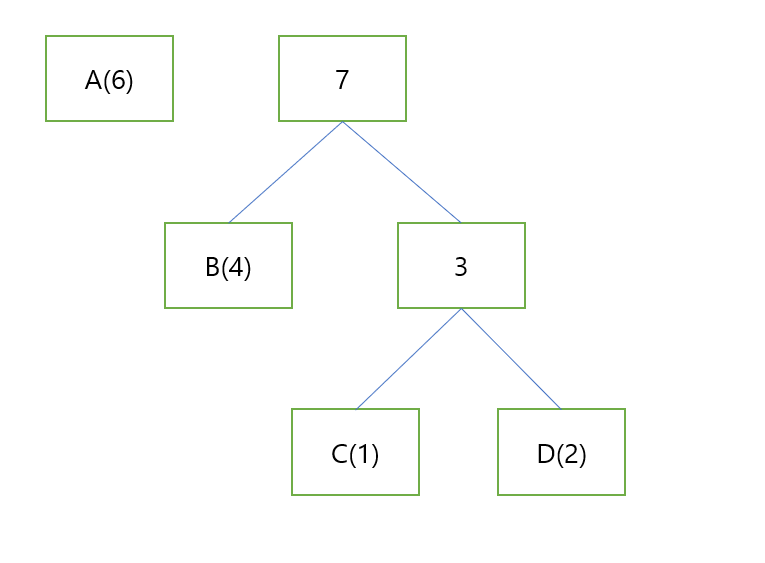
이와 같이 한번 더 묶어줍니다.
마지막 남은 A까지 묶어주면 다음과 같은 그림이 나옵니다.
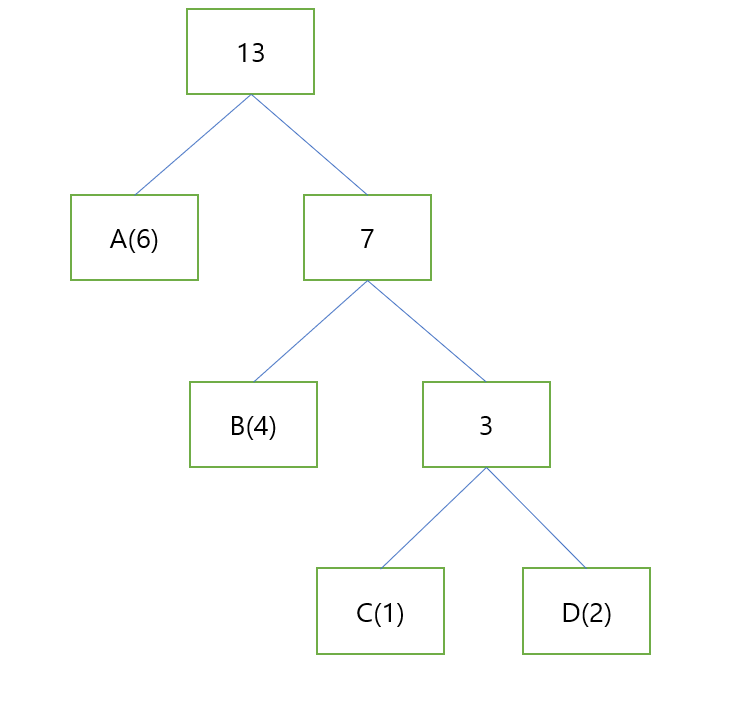
이제 루트 노드를 기준으로 왼쪽으로 한번 가면 0, 오른쪽으로 가면 1이라고 하겠습니다.
그럼 A 는 0, B는 10, C는 110, D는 111로 나타낼 수 있습니다.
이를 사용하여 AAAAAABBBBCDD을 나타내면 00000010101010110111111이 됩니다.
이와 같이 문자의 사용 빈도를 이용하여 문자열을 압축하는 알고리즘이 허프만 알고리즘입니다.
이 문제를 사용할 때는 위에 설명해드렸던 허프만 알고리즘을 이용하여 가장 사용 빈도가 작은, 즉 가장 파일의 용량이 적은 파일부터 합쳐가면 문제를 해결할 수 있습니다.
import java.io.*;
import java.util.*;
public class Main {
static Queue<Long> answer = new LinkedList<>();
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int T = Integer.parseInt(br.readLine());
while(T-->0){
int K = Integer.parseInt(br.readLine());
StringTokenizer st = new StringTokenizer(br.readLine());
Queue<Long> q = new PriorityQueue<>();
for(int i = 0; i<K; i++)
q.offer(Long.parseLong(st.nextToken()));
fileCombine(q);
}
while(!answer.isEmpty())
System.out.println(answer.poll());
}
static void fileCombine(Queue<Long> q){
long sum = 0;
while(q.size() > 1){
long firstNum = q.poll();
long secondNum = q.poll();
sum += firstNum + secondNum;
q.offer(firstNum + secondNum);
}
answer.offer(sum);
}
}'알고리즘 > 자료구조' 카테고리의 다른 글
| 백준 16562번 : 친구비 java (1) | 2022.07.20 |
|---|---|
| 백준 1717번 : 집합의 표현 java (0) | 2022.06.30 |
| 백준 1043번 : 거짓말 java (0) | 2022.06.29 |
| 백준 1976번 : 여행 가자 java (0) | 2022.06.29 |
| 백준 20040번 : 사이클 게임 java (0) | 2022.06.29 |




댓글