스프링부트를 이용한 프로젝트를 진행하면서 공간 좌표를 다룰 수 있는 기회를 가질 수 있었습니다.
요구 사항은 서울시에서 관리하는 여러 공공 쉼터들의 데이터를 DB에 저장해 놓고 사용자가 앱을 이용하면 해당 사용자의 근방 Nm에 있는 쉼터 정보를 모두 프론트로 넘겨주어야 하는 것이었습니다.
해당 요구 사항을 만족시키기 위해서 구현한 내용 및 리팩토링 과정을 소개하도록 하겠습니다.
MySQL st_distance_sphere 함수를 이용한 공간 좌표 활용
저는 공간 좌표를 다루기 위해서 우선 저에게 제일 익숙한 DBMS인 MySQL을 사용하였습니다. 아래와 같은 도메인을 만들었고 경도, 위도를 따로 저장하여 활용하였습니다.
package com.shwimping.be.place.domain;
import com.shwimping.be.bookmark.domain.BookMark;
import com.shwimping.be.place.domain.type.Category;
import com.shwimping.be.review.domain.Review;
import jakarta.persistence.CascadeType;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import jakarta.persistence.EnumType;
import jakarta.persistence.Enumerated;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import jakarta.persistence.OneToMany;
import jakarta.persistence.Table;
import java.time.LocalTime;
import java.util.List;
import lombok.AccessLevel;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
@Table(name = "place")
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Place {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long id;
@Column(name = "name", nullable = false)
private String name;
@Column(name = "region", nullable = false)
private String region;
@Enumerated(EnumType.STRING)
@Column(name = "category", nullable = false)
private Category category;
@Column(name = "address", nullable = false)
private String address;
@Column(name = "open_time", nullable = false)
private LocalTime openTime;
@Column(name = "close_time", nullable = false)
private LocalTime closeTime;
@Column(name = "rest_info", nullable = false)
private String restInfo;
@Column(name = "latitude", nullable = false)
private Double latitude;
@Column(name = "longitude", nullable = false)
private Double longitude;
@OneToMany(mappedBy = "place", orphanRemoval = true, cascade = CascadeType.REMOVE)
private List<Review> reviewList;
@OneToMany(mappedBy = "place", orphanRemoval = true, cascade = CascadeType.REMOVE)
private List<BookMark> bookMarkList;
@Builder
public Place(String name, String region, Category category, String address, LocalTime openTime, LocalTime closeTime,
String restInfo, Double latitude, Double longitude) {
this.name = name;
this.region = region;
this.category = category;
this.address = address;
this.openTime = openTime;
this.closeTime = closeTime;
this.restInfo = restInfo;
this.latitude = latitude;
this.longitude = longitude;
}
}
해당 테이블에서 필요한 여러 조건을 처리하기 위해서 QueryDSL을 사용하였고, 여러 where, order by 등의 옵션이 들어가게 되었는데 이러한 부분들보다는 공간 좌표 자체에 집중하기 위해서 해당 부분들의 코드는 제외하고 생성된 query 중 중요한 부분만 남겨서 진행하도록 하겠습니다.
제가 처음 코드를 작성하면서 사용한 sql 함수는 st_distance_sphere였습니다. 해당 함수를 사용하여 기능을 모두 구현한 후 성능에 대한 테스트를 진행해 보았습니다.
성능을 확인하기 위해서 사용한 코드는 아래와 같습니다.
explain analyze
select *
from place p1_0
left join
review rl1_0
on p1_0.id = rl1_0.place_id
where st_distance_sphere(point(127.0965824, 37.47153792), point(p1_0.longitude, p1_0.latitude)) <= 1000
and p1_0.category in ("SMART", "HOT", "COLD", "LIBRARY", "TOGETHER")이때 거리가 주어졌을 때 해당 거리 안에 있는 좌표들을 모두 가져와야 하기 때문에 거리를 1000m, 5000m, 20000m, 50000m, 100000m로 설정하면서 테스트를 진행하였습니다. 또한 서울시에서 제공하는 쉼터들을 모두 DB에 넣어두었는데 이 데이터의 개수는 4200개입니다.
각각의 거리에 따른 MySQL의 실행 계획은 아래와 같았습니다.
1000m 실행 계획
-> Left hash join (rl1_0.place_id = p1_0.id) (cost=2144 rows=21345) (actual time=4.44..46.2 rows=14 loops=1)
-> Filter: ((st_distance_sphere(<cache>(point(127.0965824,37.47153792)),point(p1_0.longitude,p1_0.latitude)) <= 1000) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=451 rows=2134) (actual time=4.39..46.1 rows=7 loops=1)
-> Table scan on p1_0 (cost=451 rows=4269) (actual time=0.0101..4.61 rows=4199 loops=1)
-> Hash
-> Table scan on rl1_0 (cost=0.00489 rows=10) (actual time=0.0314..0.0363 rows=10 loops=1)
5000m 실행 계획
-> Left hash join (rl1_0.place_id = p1_0.id) (cost=2144 rows=21345) (actual time=0.438..47.4 rows=243 loops=1)
-> Filter: ((st_distance_sphere(<cache>(point(127.0965824,37.47153792)),point(p1_0.longitude,p1_0.latitude)) <= 5000) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=451 rows=2134) (actual time=0.396..47.3 rows=236 loops=1)
-> Table scan on p1_0 (cost=451 rows=4269) (actual time=0.0084..4.7 rows=4199 loops=1)
-> Hash
-> Table scan on rl1_0 (cost=0.00489 rows=10) (actual time=0.0262..0.0309 rows=10 loops=1)
20000m 실행 계획
-> Left hash join (rl1_0.place_id = p1_0.id) (cost=2144 rows=21345) (actual time=0.101..60 rows=3282 loops=1)
-> Filter: ((st_distance_sphere(<cache>(point(127.0965824,37.47153792)),point(p1_0.longitude,p1_0.latitude)) <= 20000) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=451 rows=2134) (actual time=0.0513..59.1 rows=3275 loops=1)
-> Table scan on p1_0 (cost=451 rows=4269) (actual time=0.0106..6.9 rows=4199 loops=1)
-> Hash
-> Table scan on rl1_0 (cost=0.00489 rows=10) (actual time=0.0297..0.0365 rows=10 loops=1)
50000m 실행 계획
-> Left hash join (rl1_0.place_id = p1_0.id) (cost=2144 rows=21345) (actual time=0.0847..52.7 rows=4206 loops=1)
-> Filter: ((st_distance_sphere(<cache>(point(127.0965824,37.47153792)),point(p1_0.longitude,p1_0.latitude)) <= 50000) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=451 rows=2134) (actual time=0.0424..51.7 rows=4199 loops=1)
-> Table scan on p1_0 (cost=451 rows=4269) (actual time=0.0085..6.13 rows=4199 loops=1)
-> Hash
-> Table scan on rl1_0 (cost=0.00489 rows=10) (actual time=0.0258..0.0307 rows=10 loops=1)
100000m 실행 계획
-> Left hash join (rl1_0.place_id = p1_0.id) (cost=2144 rows=21345) (actual time=0.104..53.8 rows=4206 loops=1)
-> Filter: ((st_distance_sphere(<cache>(point(127.0965824,37.47153792)),point(p1_0.longitude,p1_0.latitude)) <= 100000) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=451 rows=2134) (actual time=0.0496..52.1 rows=4199 loops=1)
-> Table scan on p1_0 (cost=451 rows=4269) (actual time=0.0116..6.33 rows=4199 loops=1)
-> Hash
-> Table scan on rl1_0 (cost=0.00489 rows=10) (actual time=0.033..0.0395 rows=10 loops=1)
위 내용을 표로 정리하면 아래와 같습니다.
| 1000m | 5000m | 20000m | 50000m | 100000m |
| 4.44..46.2 | 0.438..47.4 | 0.101..60 | 0.0847..52.7 | 0.104..53.8 |
위의 표에서 .. 앞이 최소 시간, 뒤의 시간이 최대 소요 시간으로 단위는 ms입니다.
분명 많은 거리를 검색해야 해서 데이터가 많으면 소요 시간이 길고 적은 거리를 검색해야 하면 소요 시간이 적어야 하는데 위의 결과를 보면 항상 비슷한 시간이 걸리는 것을 확인할 수 있었습니다.
이는 st_distance_sphere 함수가 항상 모든 row에 대해서 연산을 하기 때문이라는 것을 알 수 있었습니다.
현재 row가 4200개 밖에 없기 때문에 오랜 시간이 걸리지 않지만 데이터가 많아짐에 따라 해당 함수를 사용하는 것은 큰 문제가 발생할 수 있을 것이라 생각하여 42만 개의 데이터 상황에서 위의 테스트를 다시 진행하였습니다.
1000m 실행 계획
-> Nested loop left join (cost=216822 rows=696042) (actual time=12.4..5731 rows=707 loops=1)
-> Filter: ((st_distance_sphere(<cache>(point(127.0965824,37.47153792)),point(p1_0.longitude,p1_0.latitude)) <= 1000) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=42812 rows=208812) (actual time=12.4..5719 rows=700 loops=1)
-> Table scan on p1_0 (cost=42812 rows=417625) (actual time=0.0475..717 rows=419900 loops=1)
-> Index lookup on rl1_0 using FKn429agmmvh298piqrnnd4gbfg (place_id=p1_0.id) (cost=0.5 rows=3.33) (actual time=0.0144..0.0144 rows=0.0143 loops=700)
5000m 실행 계획
-> Nested loop left join (cost=216822 rows=696042) (actual time=0.838..5264 rows=23607 loops=1)
-> Filter: ((st_distance_sphere(<cache>(point(127.0965824,37.47153792)),point(p1_0.longitude,p1_0.latitude)) <= 5000) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=42812 rows=208812) (actual time=0.794..5177 rows=23600 loops=1)
-> Table scan on p1_0 (cost=42812 rows=417625) (actual time=0.0397..628 rows=419900 loops=1)
-> Index lookup on rl1_0 using FKn429agmmvh298piqrnnd4gbfg (place_id=p1_0.id) (cost=0.5 rows=3.33) (actual time=0.00335..0.00335 rows=424e-6 loops=23600)
20000m 실행 계획
-> Nested loop left join (cost=216822 rows=696042) (actual time=0.0694..6544 rows=327507 loops=1)
-> Filter: ((st_distance_sphere(<cache>(point(127.0965824,37.47153792)),point(p1_0.longitude,p1_0.latitude)) <= 20000) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=42812 rows=208812) (actual time=0.0532..5485 rows=327500 loops=1)
-> Table scan on p1_0 (cost=42812 rows=417625) (actual time=0.0269..649 rows=419900 loops=1)
-> Index lookup on rl1_0 using FKn429agmmvh298piqrnnd4gbfg (place_id=p1_0.id) (cost=0.5 rows=3.33) (actual time=0.00294..0.00295 rows=30.5e-6 loops=327500)
50000m 실행 계획
-> Nested loop left join (cost=216822 rows=696042) (actual time=0.0914..7139 rows=419907 loops=1)
-> Filter: ((st_distance_sphere(<cache>(point(127.0965824,37.47153792)),point(p1_0.longitude,p1_0.latitude)) <= 50000) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=42812 rows=208812) (actual time=0.076..5782 rows=419900 loops=1)
-> Table scan on p1_0 (cost=42812 rows=417625) (actual time=0.0365..673 rows=419900 loops=1)
-> Index lookup on rl1_0 using FKn429agmmvh298piqrnnd4gbfg (place_id=p1_0.id) (cost=0.5 rows=3.33) (actual time=0.00294..0.00294 rows=23.8e-6 loops=419900)
100000m 실행 계획
-> Nested loop left join (cost=216822 rows=696042) (actual time=0.0755..7877 rows=419907 loops=1)
-> Filter: ((st_distance_sphere(<cache>(point(127.0965824,37.47153792)),point(p1_0.longitude,p1_0.latitude)) <= 100000) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=42812 rows=208812) (actual time=0.0573..6393 rows=419900 loops=1)
-> Table scan on p1_0 (cost=42812 rows=417625) (actual time=0.0279..745 rows=419900 loops=1)
-> Index lookup on rl1_0 using FKn429agmmvh298piqrnnd4gbfg (place_id=p1_0.id) (cost=0.5 rows=3.33) (actual time=0.00321..0.00321 rows=23.8e-6 loops=419900)
위 내용을 다시 표로 정리하면 아래와 같습니다.
| 1000m | 5000m | 20000m | 50000m | 100000m |
| 12.4..5731 | 0.838..5264 | 0.0694..6544 | 0.0914..7139 | 0.0755..7877 |
제가 예상한 대로 데이터가 많아지자 요청 한 번에 5 ~ 8초의 시간이 걸리는 문제가 발생하였습니다.
따라서 위와 같은 구현은 문제가 있다고 판단하였고 다른 구현 방식을 찾게 되었습니다.
MySQL 공간 인덱스 활용
위 상황에서 발생한 문제를 해결하기 위하여 저는 MySQL에서 지원하는 공간 인덱스를 활용하기로 결정하였습니다.
해당 기능은 모든 row에 대해서 연산이 들어가는 문제를 해결할 수 있다고 판단하였고, 도메인을 아래와 같이 경도, 위도의 값을 가지고 있는 Point 타입으로 좌표를 저장하였습니다.
@Table(name = "place", indexes = {
@Index(name = "idx_place_location", columnList = "location")
})
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Place {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long id;
@Column(name = "name", nullable = false)
private String name;
@Column(name = "region", nullable = false)
private String region;
@Enumerated(EnumType.STRING)
@Column(name = "category", nullable = false)
private Category category;
@Column(name = "address", nullable = false)
private String address;
@Column(name = "open_time", nullable = false)
private LocalTime openTime;
@Column(name = "close_time", nullable = false)
private LocalTime closeTime;
@Column(name = "rest_info", nullable = false)
private String restInfo;
@Column(name = "location", nullable = false, columnDefinition = "POINT SRID 4326")
private Point location;
@OneToMany(mappedBy = "place", orphanRemoval = true, cascade = CascadeType.REMOVE)
private List<Review> reviewList;
@OneToMany(mappedBy = "place", orphanRemoval = true, cascade = CascadeType.REMOVE)
private List<BookMark> bookMarkList;
@Builder
public Place(String name, String region, Category category, String address, LocalTime openTime, LocalTime closeTime,
String restInfo, Point location) {
this.name = name;
this.region = region;
this.category = category;
this.address = address;
this.openTime = openTime;
this.closeTime = closeTime;
this.restInfo = restInfo;
this.location = location;
}
}또한 st_contains 함수와 st_buffer 함수를 이용하여 사용자의 근방 Nm 안에 좌표가 있는지를 확인하였습니다.
해당 기능들을 사용했을 때의 성능을 테스트하기 위해서 아래와 같은 쿼리를 이용하여 실행 계획을 확인하였습니다. 우선 4200개의 데이터가 있는 상황에서의 성능을 확인하였습니다.
EXPLAIN ANALYZE
select *
from
place p1_0
left join
review rl1_0
on p1_0.id=rl1_0.place_id
where
st_contains(st_buffer(ST_PointFromText('POINT(37.47153792 127.0965824)', 4326), 100000), p1_0.location)
and p1_0.category in ("SMART", "HOT", "COLD", "LIBRARY", "TOGETHER")1000m 실행 계획
-> Left hash join (rl1_0.place_id = p1_0.id) (cost=5.05 rows=45) (actual time=0.535..0.941 rows=14 loops=1)
-> Filter: (st_contains(<cache>(st_buffer(st_pointfromtext('POINT(37.47153792 127.0965824)',4326),1000)),p1_0.location) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=4.31 rows=4.5) (actual time=0.485..0.885 rows=7 loops=1)
-> Index range scan on p1_0 using idx_place_location over (location unprintable_geometry_value) (cost=4.31 rows=9) (actual time=0.0835..0.134 rows=9 loops=1)
-> Hash
-> Table scan on rl1_0 (cost=0.282 rows=10) (actual time=0.0285..0.035 rows=10 loops=1)
5000m 실행 계획
-> Left hash join (rl1_0.place_id = p1_0.id) (cost=137 rows=1360) (actual time=0.526..29.5 rows=237 loops=1)
-> Filter: (st_contains(<cache>(st_buffer(st_pointfromtext('POINT(37.47153792 127.0965824)',4326),5000)),p1_0.location) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=123 rows=136) (actual time=0.479..29.3 rows=230 loops=1)
-> Index range scan on p1_0 using idx_place_location over (location unprintable_geometry_value) (cost=123 rows=272) (actual time=0.0883..2.38 rows=317 loops=1)
-> Hash
-> Table scan on rl1_0 (cost=0.0135 rows=10) (actual time=0.0264..0.0327 rows=10 loops=1)
20000m 실행 계획
-> Left hash join (rl1_0.place_id = p1_0.id) (cost=1759 rows=17515) (actual time=2.02..242 rows=3271 loops=1)
-> Filter: (st_contains(<cache>(st_buffer(st_pointfromtext('POINT(37.47153792 127.0965824)',4326),20000)),p1_0.location) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=451 rows=1752) (actual time=1.82..241 rows=3264 loops=1)
-> Table scan on p1_0 (cost=451 rows=4269) (actual time=0.0183..7.93 rows=4199 loops=1)
-> Hash
-> Table scan on rl1_0 (cost=0.00501 rows=10) (actual time=0.0471..0.185 rows=10 loops=1)
50000m 실행 계획
-> Left hash join (rl1_0.place_id = p1_0.id) (cost=2144 rows=21345) (actual time=0.212..239 rows=4206 loops=1)
-> Filter: (st_contains(<cache>(st_buffer(st_pointfromtext('POINT(37.47153792 127.0965824)',4326),50000)),p1_0.location) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=451 rows=2134) (actual time=0.177..237 rows=4199 loops=1)
-> Table scan on p1_0 (cost=451 rows=4269) (actual time=0.0068..8.24 rows=4199 loops=1)
-> Hash
-> Table scan on rl1_0 (cost=0.00489 rows=10) (actual time=0.0206..0.0254 rows=10 loops=1)
100000m 실행 계획
-> Left hash join (rl1_0.place_id = p1_0.id) (cost=2144 rows=21345) (actual time=0.344..234 rows=4206 loops=1)
-> Filter: (st_contains(<cache>(st_buffer(st_pointfromtext('POINT(37.47153792 127.0965824)',4326),100000)),p1_0.location) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=451 rows=2134) (actual time=0.255..233 rows=4199 loops=1)
-> Table scan on p1_0 (cost=451 rows=4269) (actual time=0.012..7.68 rows=4199 loops=1)
-> Hash
-> Table scan on rl1_0 (cost=0.00489 rows=10) (actual time=0.0342..0.0412 rows=10 loops=1)
위의 내용을 정리하면 아래와 같습니다.
| 1000m | 5000m | 20000m | 50000m | 100000m |
| 0.535..0.941 | 0.526..29.5 | 2.02..242 | 0.212..239 | 0.344..234 |
확실히 적은 범위의 데이터에 대해서 검색을 진행하면 공간 인덱스를 활용하였기 때문에 적은 시간이 걸리는 것을 확인할 수 있었습니다.
하지만 위의 방식에서 넓은 범위, 즉 많은 데이터를 가져오는 경우 기존의 코드보다 성능이 매우 저하되는 문제가 발생하였습니다.
이를 좀 더 확실하게 확인하기 위해서 42만 개의 데이터를 넣은 후 테스트를 진행해 보았습니다.
1000m 실행 계획
-> Nested loop left join (cost=834 rows=1603) (actual time=22.3..70.2 rows=707 loops=1)
-> Filter: (st_contains(<cache>(st_buffer(st_pointfromtext('POINT(37.47153792 127.0965824)',4326),1000)),p1_0.location) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=433 rows=481) (actual time=22.3..67.6 rows=700 loops=1)
-> Index range scan on p1_0 using idx_place_location over (location unprintable_geometry_value) (cost=433 rows=962) (actual time=0.123..13.5 rows=900 loops=1)
-> Index lookup on rl1_0 using FKn429agmmvh298piqrnnd4gbfg (place_id=p1_0.id) (cost=0.501 rows=3.33) (actual time=0.0033..0.00332 rows=0.0143 loops=700)
5000m 실행 계획
-> Nested loop left join (cost=21293 rows=40948) (actual time=112..2314 rows=23007 loops=1)
-> Filter: (st_contains(<cache>(st_buffer(st_pointfromtext('POINT(37.47153792 127.0965824)',4326),5000)),p1_0.location) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=11056 rows=12284) (actual time=112..2218 rows=23000 loops=1)
-> Index range scan on p1_0 using idx_place_location over (location unprintable_geometry_value) (cost=11056 rows=24569) (actual time=14.9..288 rows=31700 loops=1)
-> Index lookup on rl1_0 using FKn429agmmvh298piqrnnd4gbfg (place_id=p1_0.id) (cost=0.5 rows=3.33) (actual time=0.00376..0.00376 rows=435e-6 loops=23000)
20000m 실행 계획
-> Nested loop left join (cost=193621 rows=603237) (actual time=0.205..26222 rows=326407 loops=1)
-> Filter: (st_contains(<cache>(st_buffer(st_pointfromtext('POINT(37.47153792 127.0965824)',4326),20000)),p1_0.location) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=42812 rows=180971) (actual time=0.192..24896 rows=326400 loops=1)
-> Table scan on p1_0 (cost=42812 rows=417625) (actual time=0.0214..787 rows=419900 loops=1)
-> Index lookup on rl1_0 using FKn429agmmvh298piqrnnd4gbfg (place_id=p1_0.id) (cost=0.5 rows=3.33) (actual time=0.00365..0.00365 rows=30.6e-6 loops=326400)
50000m 실행 계획
-> Nested loop left join (cost=216822 rows=696042) (actual time=0.239..27010 rows=419907 loops=1)
-> Filter: (st_contains(<cache>(st_buffer(st_pointfromtext('POINT(37.47153792 127.0965824)',4326),50000)),p1_0.location) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=42812 rows=208812) (actual time=0.215..25315 rows=419900 loops=1)
-> Table scan on p1_0 (cost=42812 rows=417625) (actual time=0.0195..769 rows=419900 loops=1)
-> Index lookup on rl1_0 using FKn429agmmvh298piqrnnd4gbfg (place_id=p1_0.id) (cost=0.5 rows=3.33) (actual time=0.00362..0.00362 rows=23.8e-6 loops=419900)
100000m 실행 계획
-> Nested loop left join (cost=216822 rows=696042) (actual time=0.183..26411 rows=419907 loops=1)
-> Filter: (st_contains(<cache>(st_buffer(st_pointfromtext('POINT(37.47153792 127.0965824)',4326),100000)),p1_0.location) and (p1_0.category in ('SMART','HOT','COLD','LIBRARY','TOGETHER'))) (cost=42812 rows=208812) (actual time=0.166..24736 rows=419900 loops=1)
-> Table scan on p1_0 (cost=42812 rows=417625) (actual time=0.0208..768 rows=419900 loops=1)
-> Index lookup on rl1_0 using FKn429agmmvh298piqrnnd4gbfg (place_id=p1_0.id) (cost=0.5 rows=3.33) (actual time=0.00359..0.00359 rows=23.8e-6 loops=419900)
위 내용을 이전의 코드와 비교해 보겠습니다.
| 1000m | 5000m | 20000m | 50000m | 100000m | |
| mysql(전체 연산) | 12.4..5731 | 0.838..5264 | 0.0694..6544 | 0.0914..7139 | 0.0755..7877 |
| mysql(공간 인덱스) | 22.3..70.2 | 112..2314 | 0.205..26222 | 0.239..27010 | 0.183..26411 |
확실히 작은 범위에서는 공간 인덱스를 사용하는 것이 성능이 훨씬 좋지만 많은 데이터를 처리할 때는 오히려 성능이 매우 안 좋아지는 것을 확인 가능했습니다.
두 방식 모두 문제가 존재했고 이 상황을 어떻게 해결해야 하나에 대해서 고민하다가 NoSQL인 MongoDB에서 공간 인덱스를 제공하고 있고 이를 활용하면 위와 같은 문제를 해결할 수 있다 생각하여 이를 도입하기로 결정하였습니다.
MongoDB 도입
MongoDB는 NoSQL DBMS의 일종으로 Document를 기반으로 하는 시스템을 가지고 있습니다. 또한 공간 인덱스를 지원하여 공간 좌표에 대한 처리를 간단하게 해 줍니다.
위에서 MySQL에서 공간 좌표를 이용할 때는 다른 여러 라이브러리의 도움을 받아 코드를 작성해야 했습니다. 하지만 MongoDB에서는 이와 같은 작업이 필요하지 않고 DBMS 자체 기능만 사용할 수 있었습니다.
제가 MongoDB를 사용한 이유는 현재 상황에서는 서울시에서 운영하는 쉼터가 바뀌는 경우가 드물고 데이터의 갱신이 자주 일어나지 않아 조회 성능을 우선시하면 된다고 판단하여 이를 도입하였습니다.
MongoDB를 활용하기 위한 엔티티는 아래와 같습니다.
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Document(collection = "place")
public class MongoPlace {
@MongoId
@Field(name = "_id")
private String id;
@Field(name = "category")
private Category category;
@Field(name = "address")
private String address;
@GeoSpatialIndexed(type = GeoSpatialIndexType.GEO_2DSPHERE)
@Field(name = "location")
private GeoJsonPoint location;
@Indexed(unique = true)
@Field(name = "place_id")
private Long placeId;
@Builder
public MongoPlace(Category category, String address, GeoJsonPoint location, Long placeId) {
this.category = category;
this.address = address;
this.location = location;
this.placeId = placeId;
}
}쉼터 정보 조회를 위해서만 사용할 것이기 때문에 공간 좌표 등 꼭 필요한 column들만 적용하였고, 기존의 placeId를 저장해 다른 서비스에서는 기존 시스템을 그대로 사용할 수 있게 하였습니다.
MongoDB에서 위에서 한 작업과 동일한 코드를 작성하였고 성능을 검증하였습니다. 이때 사용한 코드는 아래와 같습니다.
db.place.find({
"location": {
"$near": {
"$geometry": {
"type": "Point",
"coordinates": [127.0965824, 37.47153792]
},
"$maxDistance": 1000.0
}
},
"category": {
"$in": ["SMART", "HOT", "COLD", "LIBRARY", "TOGETHER"]
}
}).explain("executionStats");위 쿼리를 사용하여 성능을 확인하였습니다.
이때 결과가 너무 길게 나왔기 때문에 일부분만 보여드리도록 하겠습니다.
1000m
executionSuccess=true, nReturned=7, executionTimeMillis=3, totalKeysExamined=97, totalDocsExamined=18분석 결과
쿼리 실행 결과 분석
기본 정보:
executionSuccess: true - 쿼리가 성공적으로 실행되었습니다.
nReturned: 7 - 쿼리 결과로 반환된 문서의 수입니다.
executionTimeMillis: 3 - 쿼리 실행에 걸린 시간은 3 밀리초입니다.
totalKeysExamined: 97 - 쿼리 처리 중 검사된 인덱스 키의 총 수입니다.
totalDocsExamined: 18 - 검사된 문서의 총 수입니다.5000m
"executionSuccess": true, "nReturned": new NumberInt("235"), "executionTimeMillis": new NumberInt("4"), "totalKeysExamined": new NumberInt("459"), "totalDocsExamined": new NumberInt("574")분석 결과
쿼리 실행 결과 분석
기본 정보:
executionSuccess: true - 쿼리가 성공적으로 실행되었습니다.
nReturned: 235 - 쿼리 결과로 반환된 문서의 수입니다.
executionTimeMillis: 4 - 쿼리 실행에 걸린 시간은 4 밀리초입니다.
totalKeysExamined: 459 - 쿼리 처리 중 검사된 인덱스 키의 총 수입니다.
totalDocsExamined: 574 - 검사된 문서의 총 수입니다.20000m
"executionSuccess": true, "nReturned": new NumberInt("3272"), "executionTimeMillis": new NumberInt("25"), "totalKeysExamined": new NumberInt("3840"), "totalDocsExamined": new NumberInt("6916")분석 결과
쿼리 실행 결과 분석
기본 정보:
executionSuccess: true - 쿼리가 성공적으로 실행되었습니다.
nReturned: 3,272 - 쿼리 결과로 반환된 문서의 수입니다.
executionTimeMillis: 25 - 쿼리 실행에 걸린 시간은 25 밀리초입니다.
totalKeysExamined: 3,840 - 쿼리 처리 중 검사된 인덱스 키의 총 수입니다.
totalDocsExamined: 6,916 - 검사된 문서의 총 수입니다.50000m
"executionSuccess": true, "nReturned": new NumberInt("4199"), "executionTimeMillis": new NumberInt("31"), "totalKeysExamined": new NumberInt("4421"), "totalDocsExamined": new NumberInt("8398")분석 결과
기본 정보:
executionSuccess: true - 쿼리가 성공적으로 실행되었습니다.
nReturned: 4199 - 쿼리 결과로 반환된 문서의 수입니다.
executionTimeMillis: 31 - 쿼리 실행에 걸린 시간은 31 밀리초입니다.
totalKeysExamined: 4421 - 쿼리 처리 중 검사된 인덱스 키의 총 수입니다.
totalDocsExamined: 8398 - 검사된 문서의 총 수입니다.100000m
"executionSuccess": true, "nReturned": new NumberInt("4199"), "executionTimeMillis": new NumberInt("34"), "totalKeysExamined": new NumberInt("4423"), "totalDocsExamined": new NumberInt("8398")분석 결과
쿼리 실행 결과 분석
기본 정보:
executionSuccess: true - 쿼리가 성공적으로 실행되었습니다.
nReturned: 4199 - 쿼리 결과로 반환된 문서의 수입니다.
executionTimeMillis: 34 - 쿼리 실행에 걸린 시간은 34 밀리초입니다.
totalKeysExamined: 4423 - 쿼리 처리 중 검사된 인덱스 키의 총 수입니다.
totalDocsExamined: 8398 - 검사된 문서의 총 수입니다.
executionStages:위의 내용을 정리하면 아래와 같습니다. 이때 이전의 실행 결과와 비교하여 보여드리겠습니다. 또한 42만 개의 데이터를 이용하여 테스트한 결과도 같이 보여드리겠습니다.
4200개 데이터
| 1000m | 5000m | 20000m | 50000m | 100000m | |
| mysql(전체 연산) | 4.44..46.2 | 0.438..47.4 | 0.101..60 | 0.0847..52.7 | 0.104..53.8 |
| mysql(공간 인덱스) | 0.535..0.941 | 0.526..29.5 | 2.02..242 | 0.212..239 | 0.344..234 |
| MongoDB | 3 | 4 | 25 | 31 | 34 |
420000개 데이터
| 1000m | 5000m | 20000m | 50000m | 100000m | |
| mysql(전체 연산) | 12.4..5731 | 0.838..5264 | 0.0694..6544 | 0.0914..7139 | 0.0755..7877 |
| mysql(공간 인덱스) | 22.3..70.2 | 112..2314 | 0.205..26222 | 0.239..27010 | 0.183..26411 |
| MongoDB | 10 | 278 | 3397 | 3982 | 4392 |
MongoDB를 활용했을 때 성능이 모든 구간에서 좋아진 것을 확인할 수 있었습니다.
위의 데이터를 최대 소요 시간을 이용하여 그래프로 그리면 아래와 같습니다.
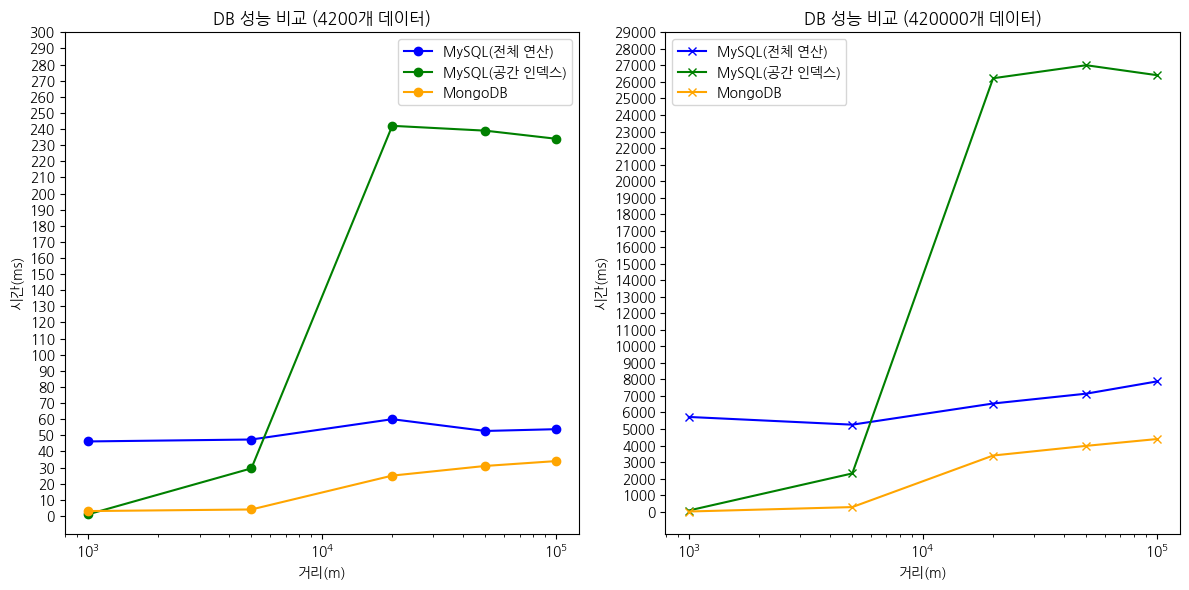
MongoDB를 사용했을 때가 모든 구간에서 성능이 좋은 것을 확인할 수 있었습니다.
MongoDB를 사용해서 MySQL을 사용했을 때보다 평균 65% 정도의 성능 향상을 이룰 수 있었습니다.
'CS > 데이터베이스' 카테고리의 다른 글
| 트랜잭션 격리 수준 (1) | 2024.03.18 |
|---|

댓글